


Building an Event-Driven Architecture at Hashnode.
Why do we need EDA & what is the current state at hashnode?


Did you ever want to know what happens once you publish a post on hashnode? This is your chance.
This is the first post of the series: Building an Event-Driven-Architecture at Hashnode
This first post gives you an idea of what Event-Driven-Architecture (EDA) is, why we need it, and what the current state of EDA at hashnode is.
Hashnode has many event-driven use cases. One use case I will use throughout this post is publishing a post. If a user publishes a post several services are launched:
- Turn this post into an audio post
- Backup this post to users' GitHub
- Send a newsletter to all subscribers
- Add user activity
- Update article circles
The actual implementation details will follow in the next posts of this series. But the stack will consist of:
- Amazon EventBridge
- Amazon Lambda
- Amazon SQS
What is Event-Driven Architecture?
First of all, let's have a look at what EDA actually is and which problems we face without it.
An Event-Driven Architecture (EDA) decouples services from each other by introducing a new entity called an event. An event is some object (you can imagine it as a simple JSON document) that will be sent to an orchestrator (event bus) that takes care of sending the event to several consumers.
For post publishing at hashnode, we can imagine this event for example:
{
"uuid": "eaeb7e90-160d-40a6-841a-74a9bf89210f",
"publication": "1234",
"postId": "5678",
"userIdWhoCalledEvent": "91011",
"hasScheduledDate": false,
"isTeamPub": false
}
Components
An EDA decouples systems. For that, we need to have several components.
Note: Several components are introduced here that are not necessarily needed for an event-driven system. Please check out the second part of this series to see how else you build event-driven systems. These components are mainly needed for an event bus model.
The main components here are:
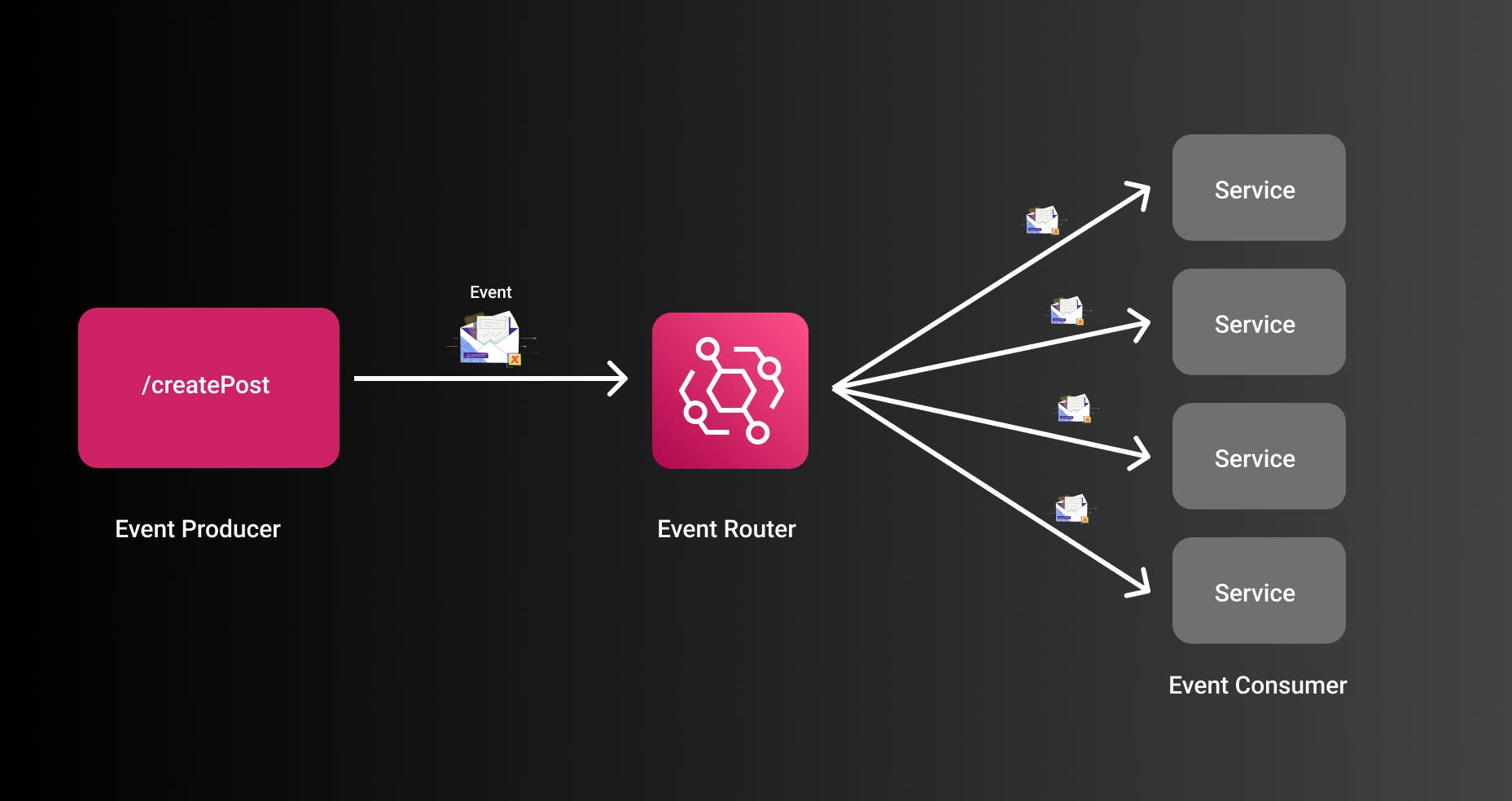
- Event Producer: The system that sends the event -> For example a REST API
- Event Routers: The system to orchestrate all events and launch the required services
- Event Consumers: The services that consume the event
- Event: The actual event consumers are working on
Why do we need an Event-Driven Architecture?
Now we know what an event-driven architecture consists of. But what are the problems we face that we need to migrate to an EDA?
Let's have a look at the top 3 reasons why we want to implement a proper EDA at hashnode.
Performance & Background Tasks
Users should have an amazing experience while using hashnode. One aspect of this is of course performance. Performance in this case is the execution time of one endpoint. For example, the time between clicking the button Publish Post and your post actually being published.
For understanding this point it is crucial to understand the difference between synchronous and asynchronous processing. Synchronous processing is often a typical REST API. The user clicks on the button Publish Post, and the browser shows a loading indicator as long as the API is processing (making DB calls, markdown to HTML, etc.).
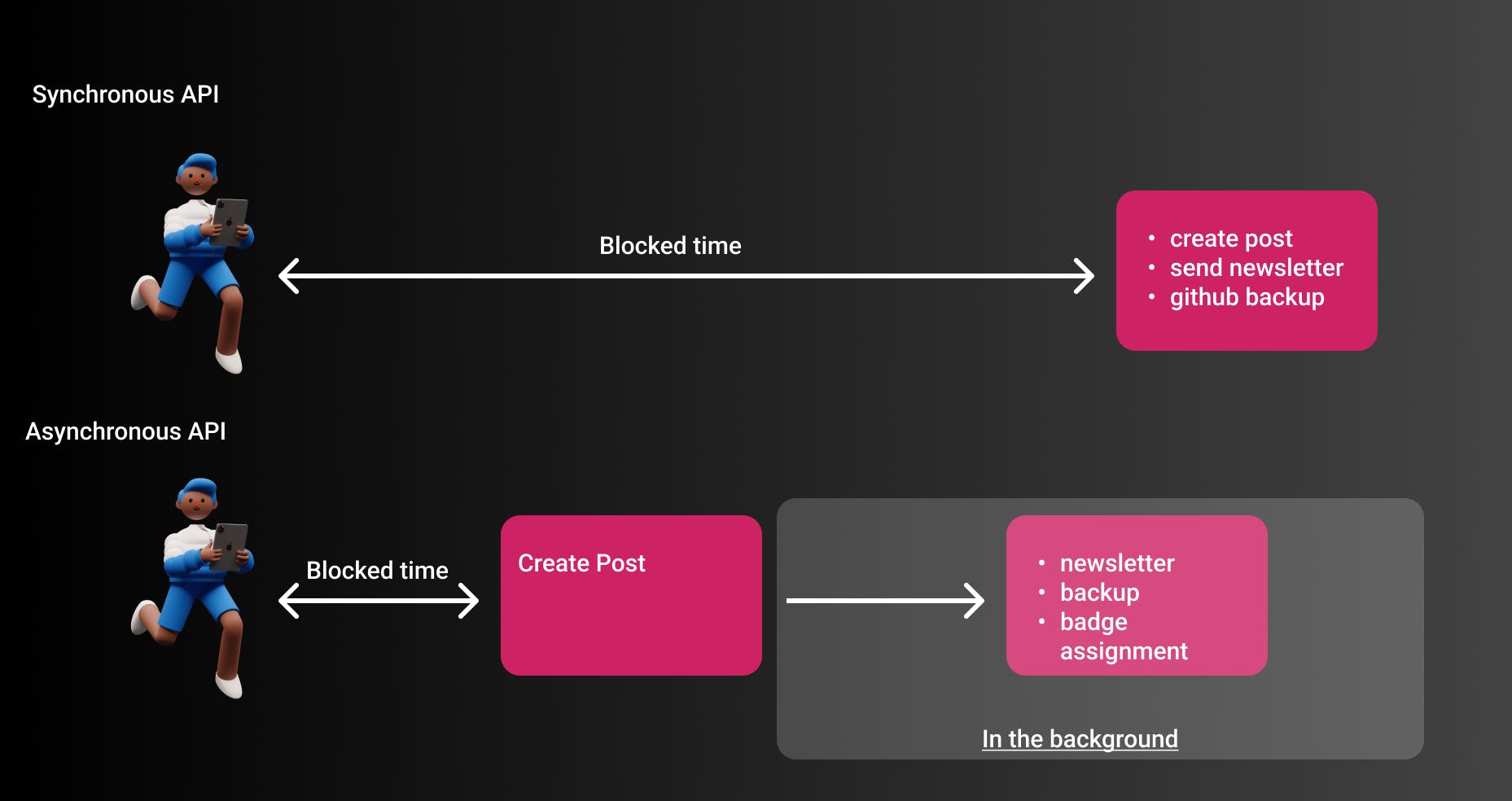
Asynchronous processing is also often referred to as background processing. The user can interact with your application again and is not blocked to continue work on your website. All other tasks will be worked on in the background.
If we would add all optional services such as
- GitHub Backup
- Badge Assignment
- Sending Newsletters
to our synchronous endpoint, it would take really long till the actual post is published and the user sees it. But if we only do the most crucial part the user needs, i.e. publishing a post, and putting all other tasks into the background we have a much nicer user experience.
By introducing an EDA we allow systems to work on these tasks asynchronous and completely independent from the actual user-facing API.
Decoupling
A second major reason is decoupling.
a measure of how closely connected two routines or modules are [1]
Decoupling means that systems and teams can work independently from each other without knowing much more than an interface or an API specification.
Coupling isn't only referring to the software modules, but it can also refer to many different things. See some examples here:
| Type | Examples |
| Technology | Java vs. C++ |
| Temporal | Sync vs. async |
| Location | IP, DNS |
One really bad case of coupling on hashnode's current state is that the event producer, i.e. the REST API needs to know which services to call in which circumstances. For example, if a post was published in a team blog and this blog has GitHub backup enabled the API needs to call the GitHub Backup service. While this is straightforward, to begin with, it doesn't scale well with more services to call and also not with having more developers on the team that should own their services.
In a coupled architecture it would look like that:
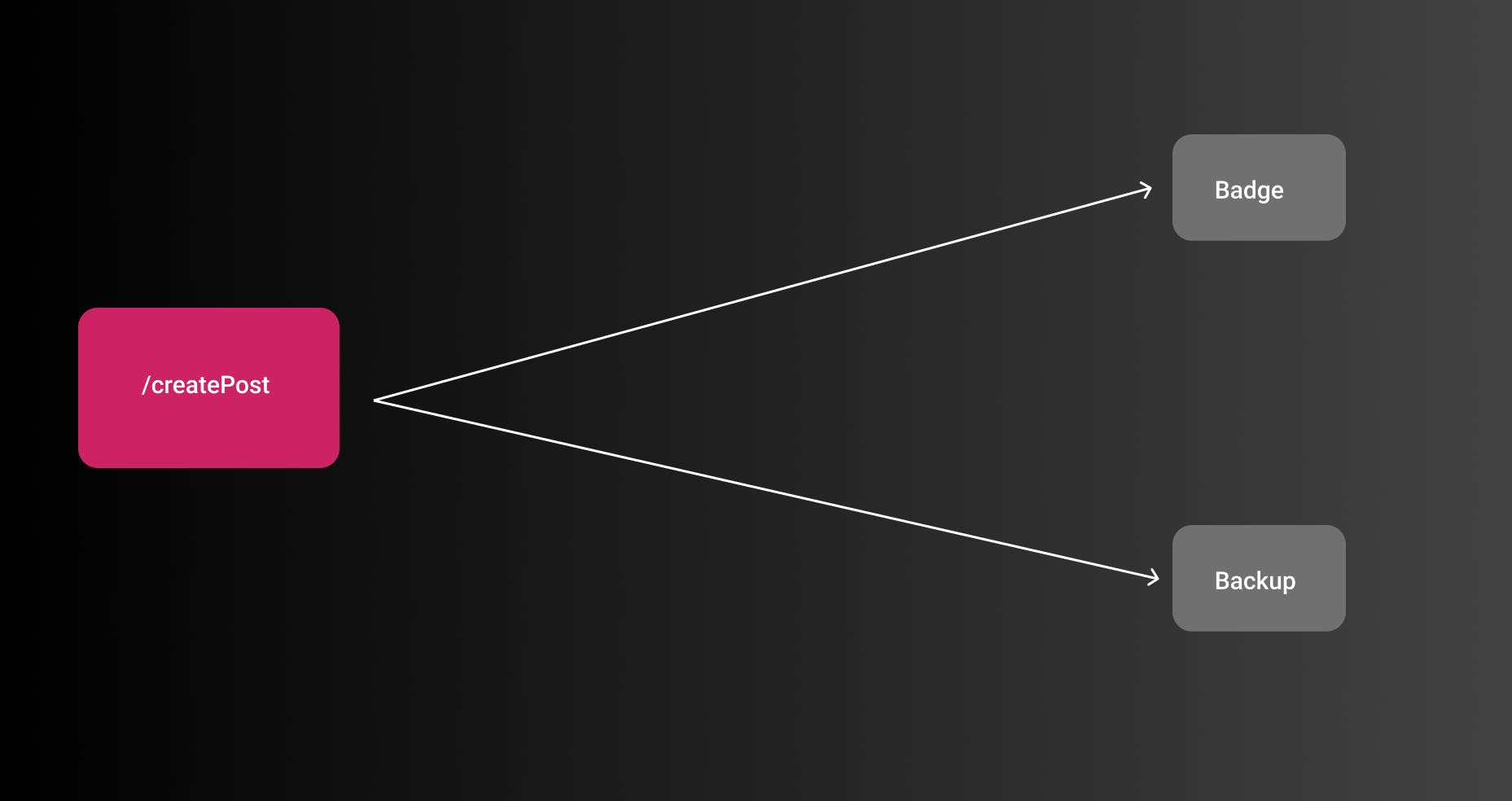
While this looks easy for one or two services with the increase of features this will get more and more complex. After a while, there are many cases where sub modules depend on each other or have to do retries in certain cases. This should be the point to think about decoupling your architecture.
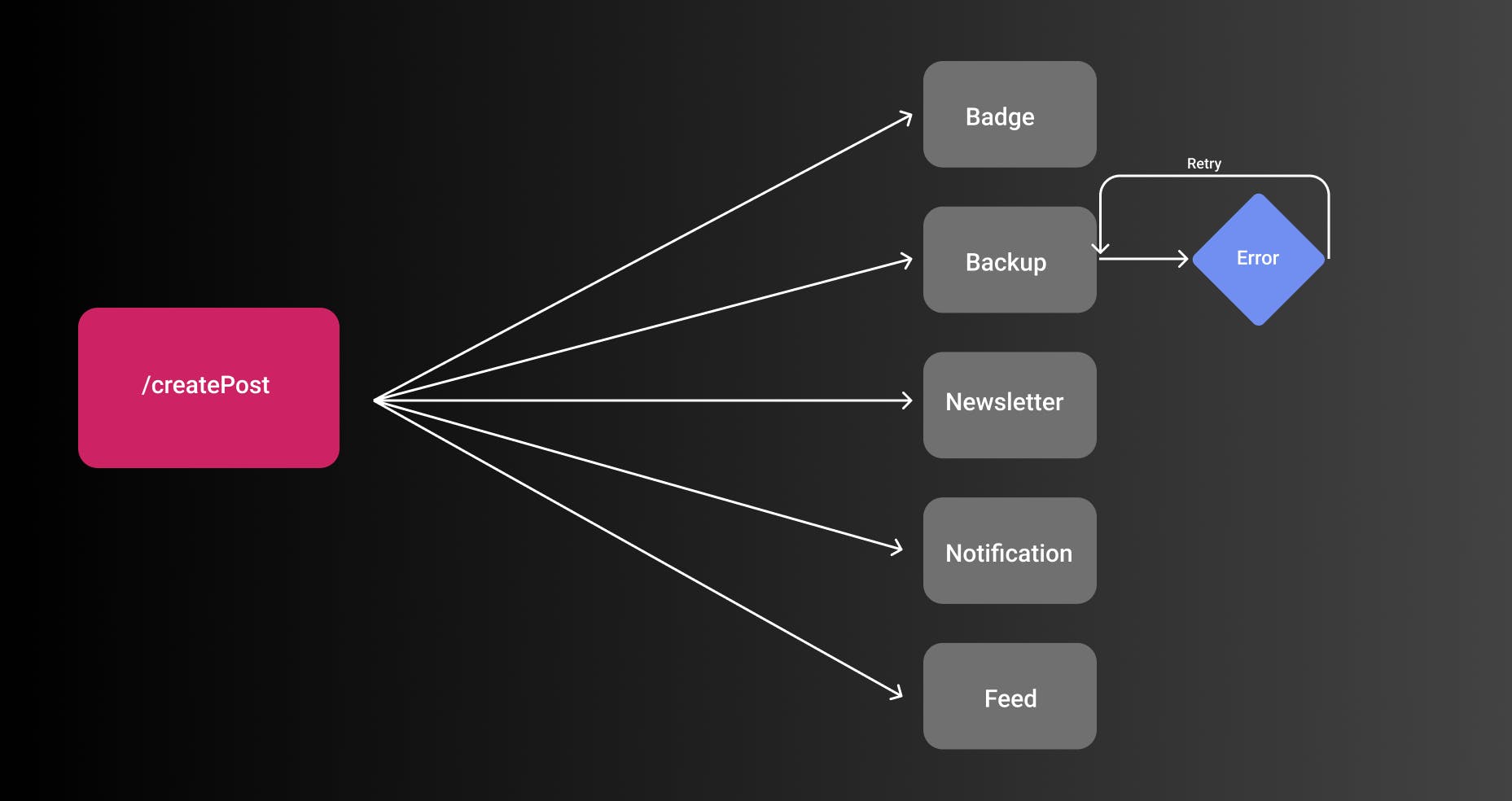
With a proper EDA, this is much easier by having consumers of events (e.g. GitHub Backup Service) subscribing to certain events. Let's see an example
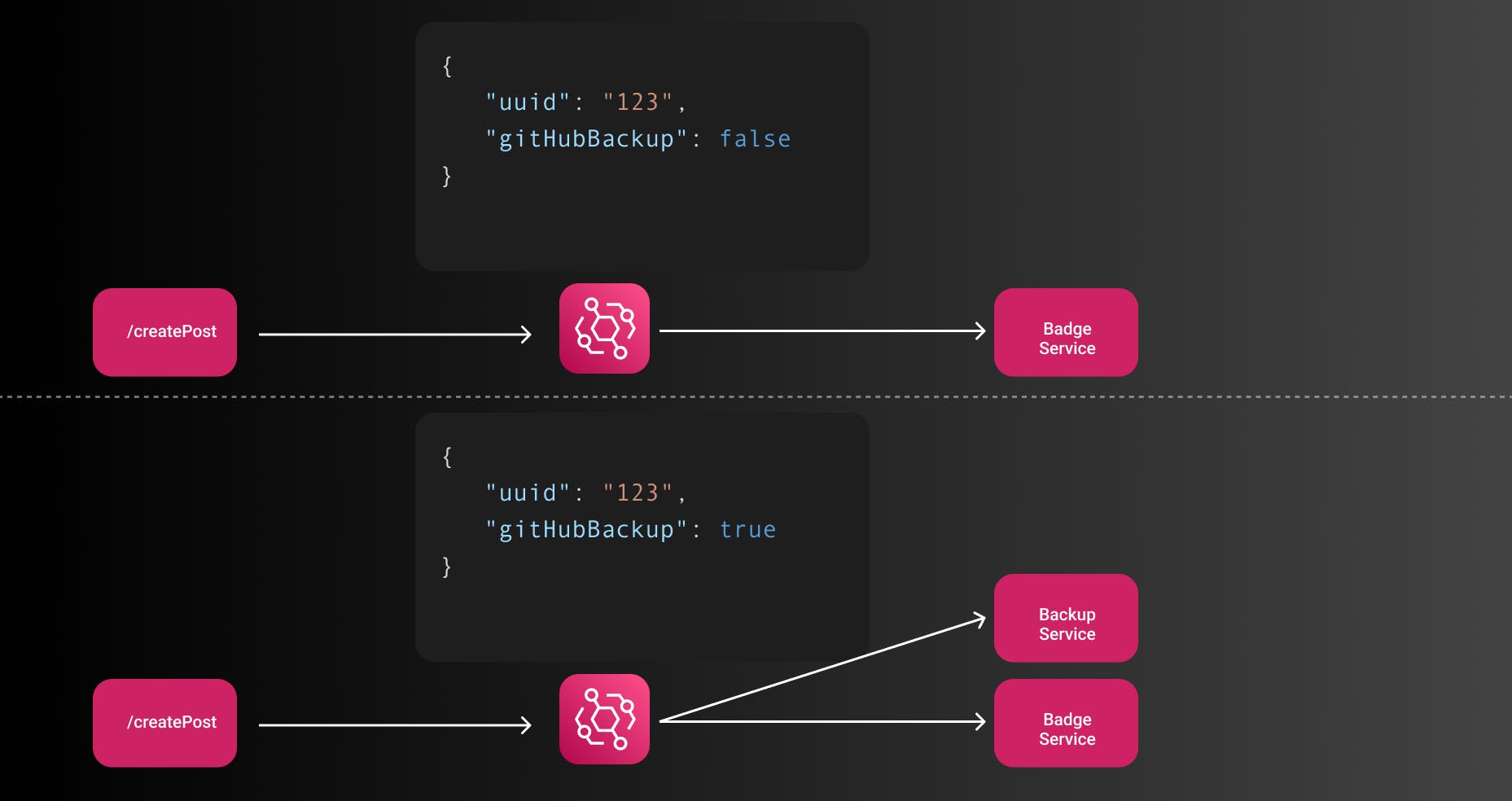
For all posts, the badge assignment will start since there is some more business logic involved. GitHub backup is dependent if a user has it enabled in their blog.
If you look at the first event, the flag for gitHubBackup is false. That means the service won't listen to the event and won't start the actual backing up of the post.
The second blog has gitHubBackup enabled and therefore launches the backup service.
While this seems super trivial it properly decouples the producer and the consumer of events. As a consumer service, you can simply check which attributes are available and create rules for them. I don't show any code for the rules here on purpose since this post is not about the implementation details.
The goal is that one endpoint simply triggers an event like postPublished, passes a pre-defined set of data, and the EventBus and event consumers subscribe to this event and take care of the rest. The producer doesn't need to know anything about it.
Scalability
The third reason is scalability.
I don't refer to scalability in terms of scaling to more users. This is the easy part.
I refer to scaling as scaling the internal platform for more developers. This is the hard part.
More developers should be able to ship more things. Everybody who worked in a high-growing environment knows that this is not necessarily true.
By decoupling the systems and implementing proper workflows for sharing event types and adding new events it will be made much easier to implement services that only listen to certain event types. This is really important for a great development experience.
Low Coupling -> More Devs -> Better DevXP -> More will be shipped 🚀
Developer experience in a serverless tech stack is a highly discussed topic and not everything is perfect yet. But by having a decoupled architecture, smaller teams or developers can really own services without the need to change code in 6 different places.
If somebody wants to develop a service based on a certain event, they are not inherently responsible for also changing the whole API endpoint.
Okay, we get it, EDA makes sense. Keep in mind that everything has trade-offs. By introducing this architecture you need to be aware of how you trace events across many different systems to be able to understand what is going on.
Current State of Hashnode
To understand Hashnode's point of view a bit better I want to give you a glimpse of our current architecture.
Hashnode had and still has immense growth. With immense growth and many new features, tech debt will be introduced automatically. That is fine. But it is also important to acknowledge that and to work on these challenges.
The main API of hashnode is a JavaScript Express Server running on a virtual machine.
We are already using some kind of "EDA" but currently, it is highly coupled with the actual REST API.
For the event handling, we use the event capabilities of Express.
Let's see an example
// controlles/post.controller.js
exports.createPost = async function (req, res) {
if (post.partOfPublication && post.publication) {
ee.emit("publication.post.published", {
post: post,
title: post.title,
url: post.url,
user: req.user,
isTeamPub,
});
}
};
On the event side we've got a globalEventListener that listens to requests:
ee.on('publication.post.published', async function (eventData) {
if (eventData.post.audioBlogEnabled) {
backup();
}
});
While this is not super bad we inherently have tight coupling. In the actual API, we check for example if a post is part of a publication and if it has a publication attached. If it has that we emit the event. Within the event listener publication.post.published we execute all business logic within that function. In the consumer, we need to check if certain flags are set, for example, the audio blog feature and act based on them.
All of that will be gone with our new EDA. The desired state is simple. The API emits an event with a pre-defined type, i.e. PostPublishedEvent, and tells the EventBus: "Hey I've published a post with the ID 123". That's it! Everything else will be taken care of.
This post series happens always a bit later than the actual migration, so no worries most of the EDA is already done 😉
References
- ISO/IEC/IEEE 24765:2010 Systems and software engineering — Vocabulary
- The Many Meanings of Event-Driven Architecture • Martin Fowler • GOTO 2017
- AWS EventBridge