

How to Build Event-Driven Architecture on AWS?
Let's see how to build event-driven systems on AWS. SQS vs. SNS Fanout vs. EventBridge


In my first post, I talked a lot about why an Event-Driven-Architecture (EDA) makes sense and what the current state at Hashnode is.
This post will shed a light on how to build event-driven systems on AWS. This is not a complete list since there are even more ways of building event-driven systems. But these are the most common architectures.
The three solutions I will focus on are:
- Message Queues with Simple Queue Service (SQS)
- Fanout Pattern with Simple Notification Service (SNS)
- EventBridge with additional services such as Lambda & SQS
What are differentiating factors?
One of the main benefits I state in my first post is decoupling systems. We don't want that the producer and consumer of events are coupled in any way.
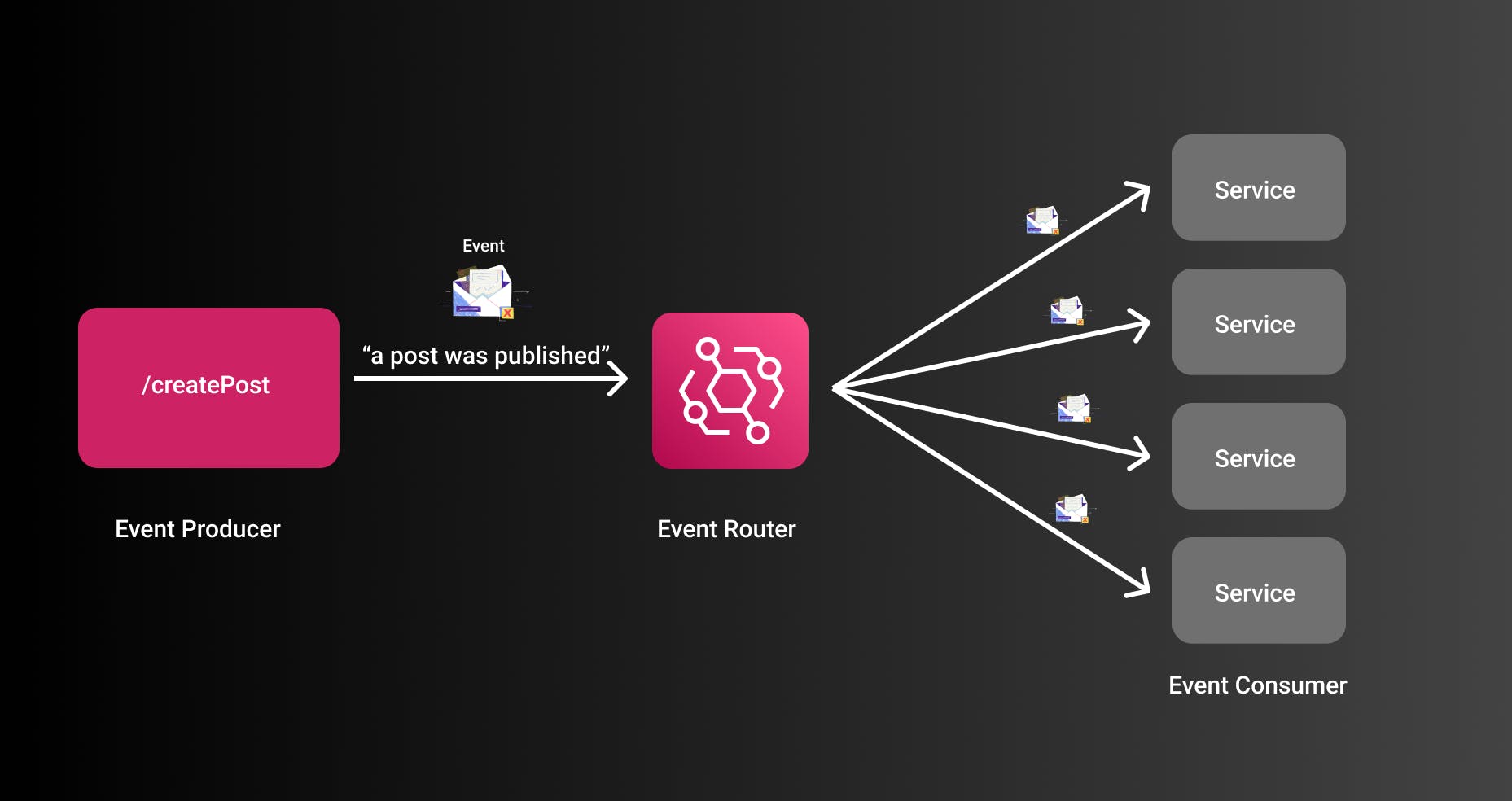
To understand this concept further let's first take a look at a system that doesn't use EDA at all.
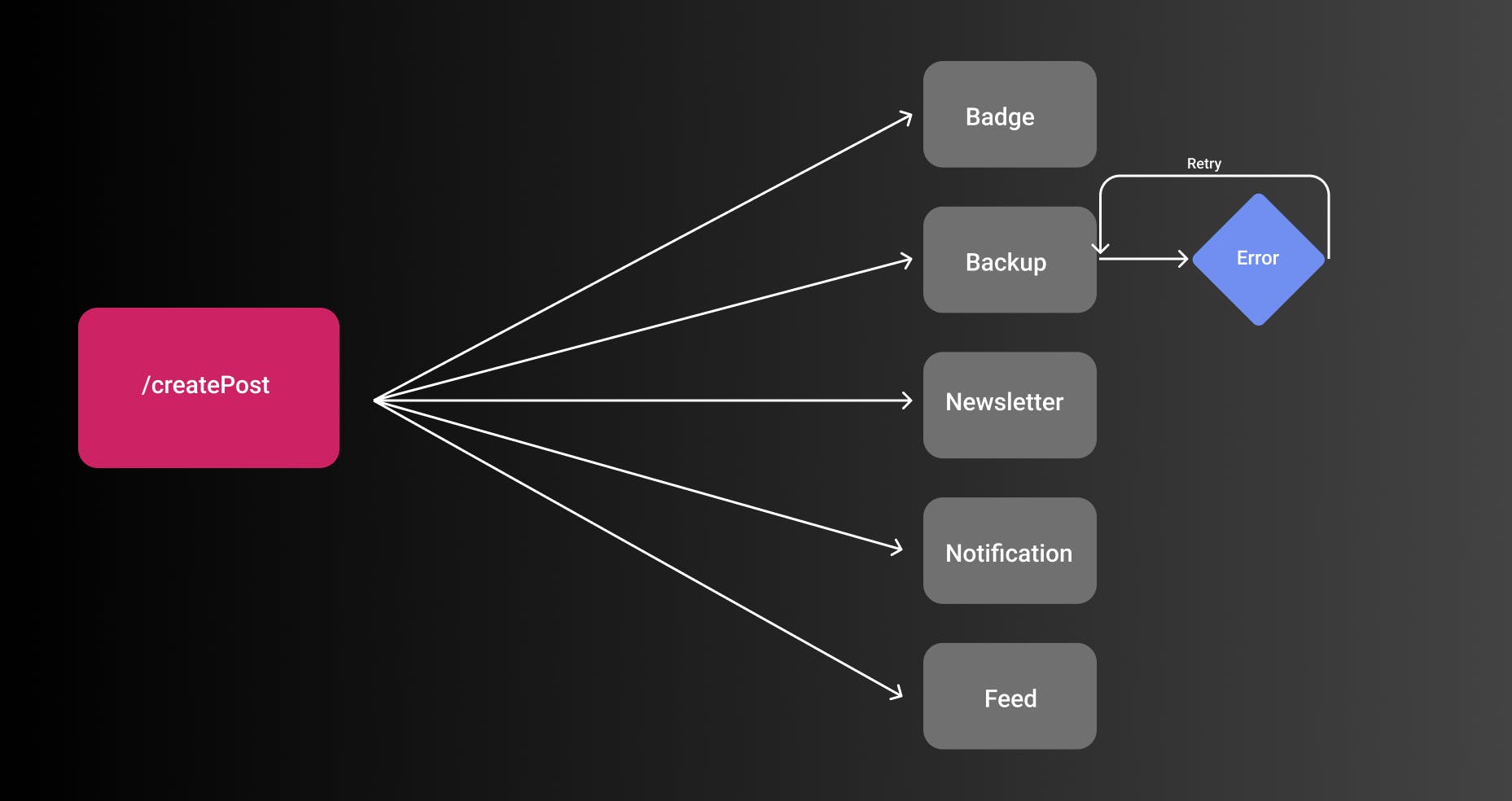
In the picture, you can see the endpoint createPost. This endpoint needs to know in which cases it calls which services. For example, if a blog is enabled to back up its posts to GitHub it needs to call the GitHub Backup Service. For a couple of services, this seems pretty easy but if you start integrating more services that can get quite complex. Especially if you start introducing proper error handling and retries.
To overcome this issue we introduce EDA. The createPost endpoint simply publishes an event postPublished and consumers decide what to do. Before the create post service told the GitHub backup service to backup this post. Now, the create post service simply says: Hey, a user published a post. The service simply doesn't care what happens next.
This method can be implemented with many different solutions. These solutions are not coupled to AWS at all but since we will use AWS I will show how to do it with AWS.
Solutions to build EDA on AWS
Now let's take a look at the different solutions we have out there.
Asynchronous Message Queue
The first model we look at is an asynchronous model. The publisher (createPost API) sends a message to a message queue. On AWS we would use Amazon Simple Queue Service (SQS) for that. SQS is a managed message queue service that allows us to send a high number of messages into the queue. The messages will be retained till a consumer picks them up and deletes them or if the defined period (retention period) is over.
The consumer in that case can be a lambda function or any other computing resource. There would be exactly one queue GitHubBackupQueue for one task.
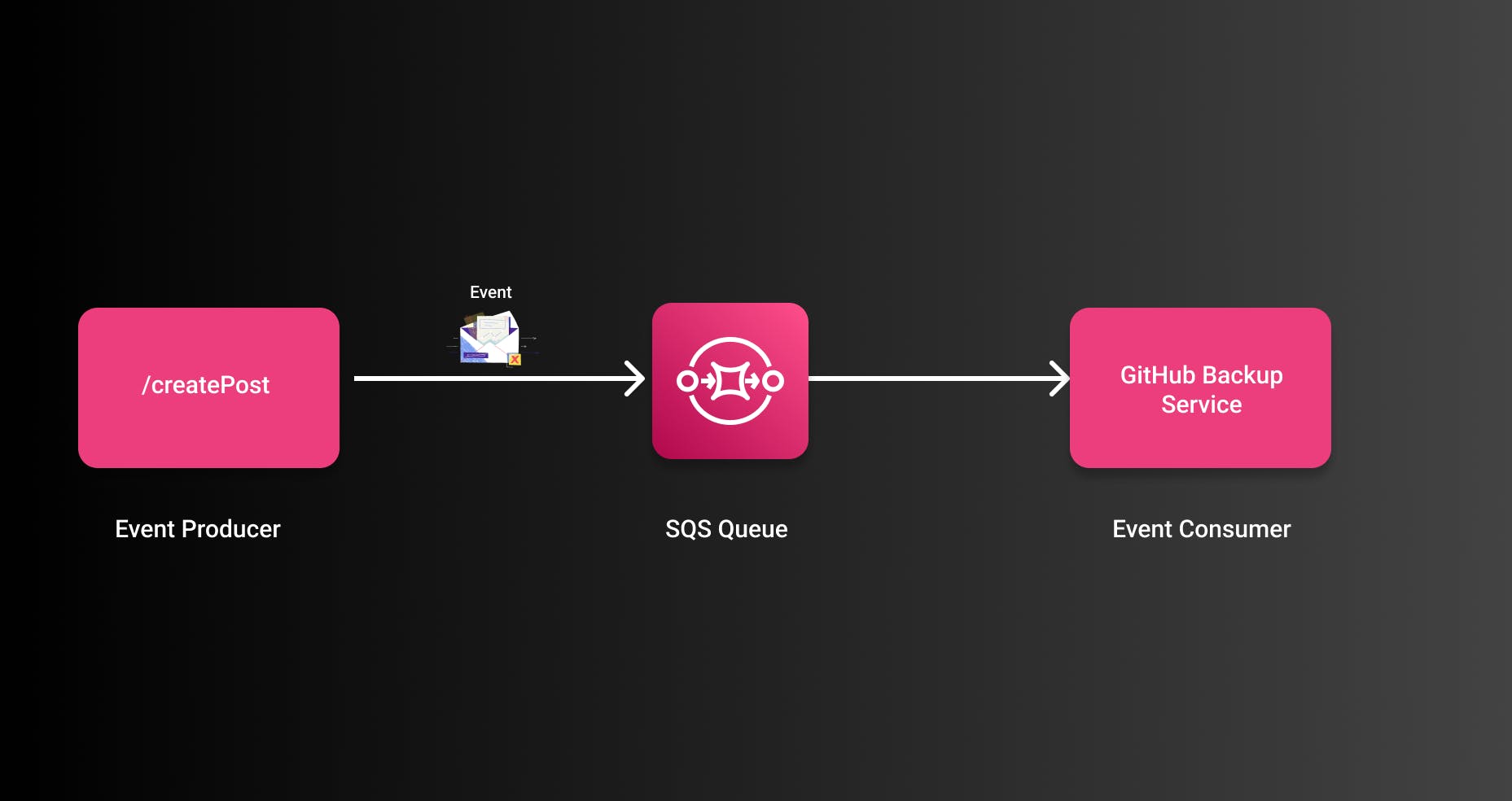
In AWS terms this is also called a asynchronous point-to-point model and I think you can see why.
The producer and the consumer have a one-to-one mapping. One producer sends the event to one consumer. The consumer has only one job, in that case backing up that post. Of course, you could move more business logic to this one consumer and let it work and several things but this will make things more complicated and we'll end up with the same coupling.
What you normally would do is to have one queue per service that gets launched. In our case, we would have several queues for
- GitHub Backup
- Audio Blog Generation
- Newsletter
We need to separate the queues to enable proper retries and error handling.
While this approach is pretty straightforward to get started, it has definitely a lot of drawbacks. But let's start with the pros.
Pros
Temporal Coupling
We get rid of or at least decrease the temporal coupling. The task can run in the background independent from the producer. The consumer decides when to start getting the messages from the queue and when to work on the message.
Consumer can fail
If the consumer fails, the message is still available and can be picked up. This is a huge benefit.
Cons
Coupling
One of the main drawbacks is that we are back to tight coupling. The producer needs to know to send the event to the GitHubBackupQueue if blogs have enabled the backup service. If we have more queues like AudioGenerationQueue and NewsletterQueue the published needs to know about that and handle the publishing of the events.
One queue per service
The scalability and extensibility is also major drawback. If we want to add more services we need to add one queue per service. This is really not scalable and not a great developer experience at all.
So let's check the next approach.
Fanout Pattern
The next pattern we look at is the Fanout Pattern. In AWS we would use the service Amazon Simple Notification Service (SNS) for that. SNS is a push-based service, in contrast to SQS which is a poll-based service. Its main purpose is to push out messages (or events) to subscribers. SNS follows a publish-subscribe model. A consumer can simply subscribe to topics and SNS publishes messages to these topics.
While SNS is often used for personal notifications such as emails or in-app notifications it can also be used for publishing messages to other applications such as SQS or Lambda.
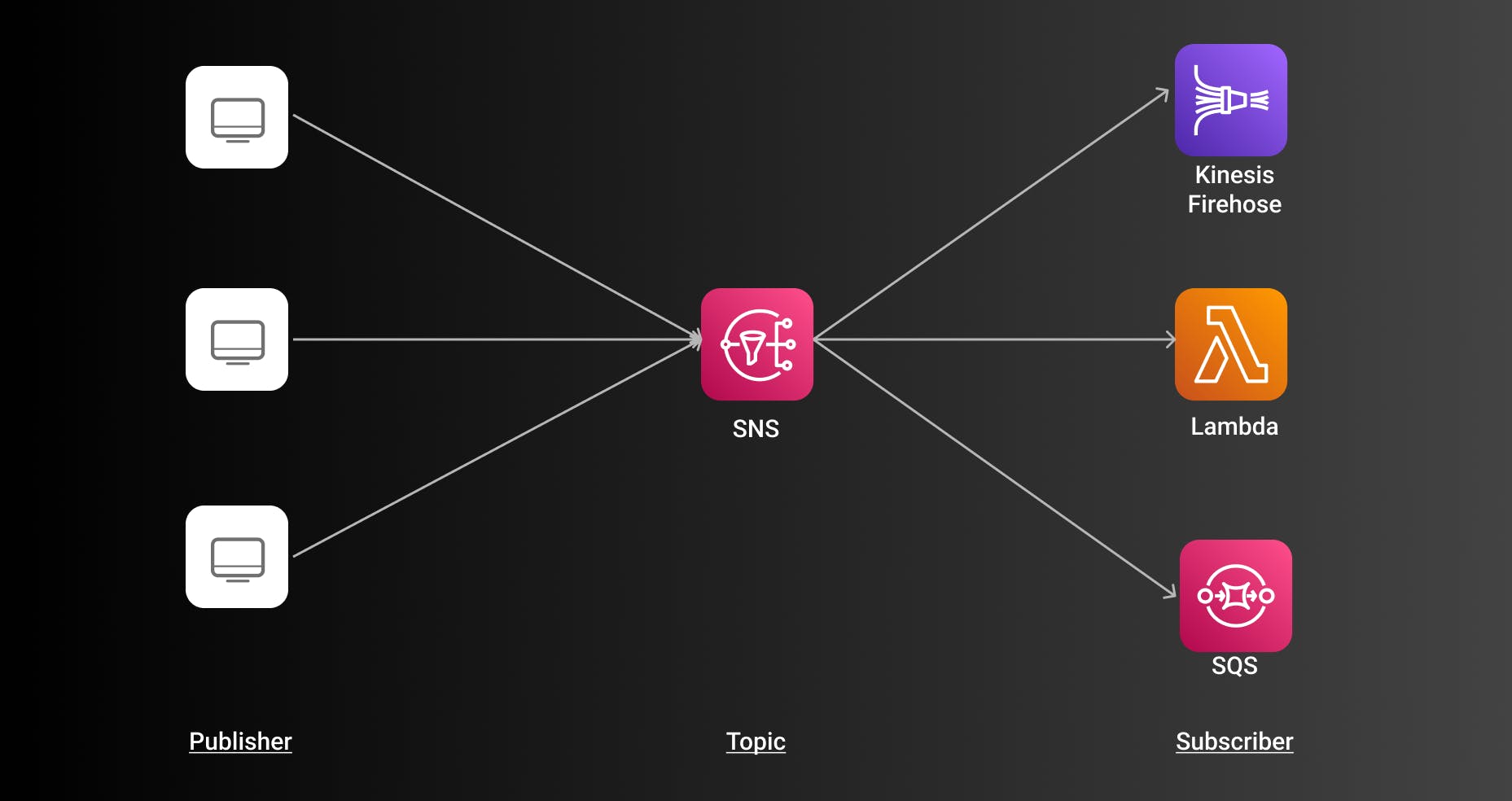
The great thing about SNS is also that it can publish to a variety of different AWS Services. For an EDA like we want to implement it would be most likely to use services such as:
- AWS Lambda
- Amazon Kinesis Firehose
- Amazon SQS
Fanout Pattern
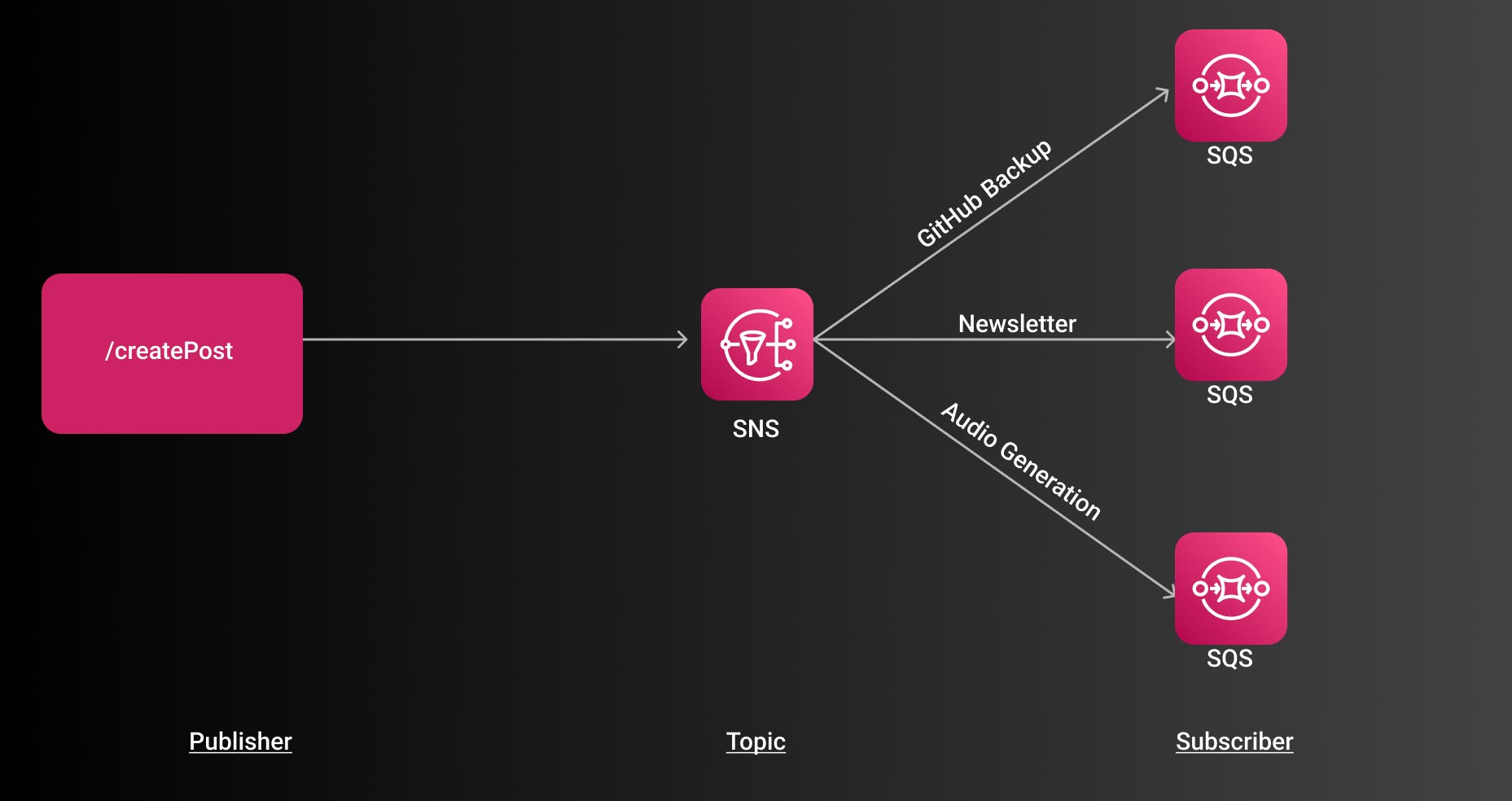
The fanout pattern describes that one event gets pushed out to many subscribers. In the case of our create post service we can imagine that services like
- GitHub Backup
- Badge Assignment
- Audio Blog Generation
- Newsletter Service
simply subscribe to the createPostTopic and listen to these events. SNS pushes out the event to all subscribers and therefore fans it out to all subscribers.
Pros
Coupling
One huge benefit is that the coupling of producer and subscriber is gone. The producer doesn't need to know all services it needs to publish to. The service only needs to know to publish a message to one topic which is the createPostTopic.
Variety of Services
SNS can use a lot of service integrations. That means we can implement proper retry and error handling by using queues as subscribers.
Publish-Subscribe
Consumers can easily subscribe to topics. This overlaps with the pro of coupling a lot. Consumers can simply choose if they should subscribe to a topic or not.
Cons
Filtering & Routing
One really important feature (for Hashnode at least) is the ability to route messages only to some subscribers based on the message body. For example, if we publish this message:
{
"metadata": {
"uuid": "d069fbf8-3d7a-4957-b547-5090c3baa187",
"userId": "user_1"
},
"data": {
"publication": { "id": "pub_1", "gitHubBackup": false },
"post": { "id": "post_1", "hasScheduledDate": true }
}
}
We don't want to route it to gitHubBackup but to the scheduleService.
With SNS this is not possible. Each consumer (e.g. lambda function) will be invoked and checked the message body. This means more code. We want less code and more configuration.
Archive
This decision is mainly based on the comparison with EventBridge. SNS doesn't offer an in-built solution for using an archive to store all messages and simply replay them. This is often needed to recover from introduced bugs or for development purposes.
Event Bus Model
The last model is called the event bus model. It is called that because it uses an event bus in the middle for routing events to the desired consumers.
AWS launched a new service called EventBridge (formerly known as CloudWatch Events) in 2019. EventBridge gives us the ability to build exactly that model.
In EventBridge we have three different components:
- EventBus: We publish events to an EventBus
- Rules: Rules decide how to route the requests
- Targets: Targets consumer events.
Pros
Routing
Consumers decide which events to consume. If we look back at our example with publishing a post:
{
"metadata": {
"uuid": "d069fbf8-3d7a-4957-b547-5090c3baa187",
"userId": "user_1"
},
"data": {
"publication": { "id": "pub_1", "gitHubBackup": false },
"post": { "id": "post_1", "hasScheduledDate": true }
}
}
The consumer gitHubBackupService can now decide to only listen to posts that have the flag githubBackup on true. Similar the ScheduleService.
Archive & Replay
EventBridge has the in-built ability to archive all events. With the archive, you have the opportunity to replay the events in a given timeframe. If you've introduced a bug and fixed it two hours later, you can simply replay all events from that given time. Considering everything is implemented in an idempotent way but I won't go into the details of that.
Flexibility
You are flexible in the type of service to use. If you have pretty simple workloads you can simply use an AWS Lambda function. If your retry & error handling is a bit more challenging you can also use SQS queues in between. The choice is up to you.
Integration with many SaaS Partners EventBridge integrates with many SaaS partners like MongoDB, Auth0, and ZenDesk. You can consume their events easily. For example, on MongoDB, you can configure triggers that will send events to EventBridge in case of file changes. This makes EventBridge super powerful!
Cons
5 Targets per Rule
If you research EventBridge a bit you will always find the limitation on 5 targets per rule. While this is true and looks pretty odd at the beginning it is for most of the applications not an issue. We'll look further into the definition of event rules but saying that there will be one rule per consumer not per target or per detail-type. That means each consumer will have one rule, even if the event pattern is the exact same. Therefore, we will always only have one target per rule.
Latency
If you compare EventBridge with SNS, EventBridge normally has a bit of higher latency. Saying that the latency is still at about half a second so for most of the applications totally fine. SNS on the other hand often has a latency below 30 ms.
Hashnode's Decision
Developing serverless applications, or developing software in general is always an iterative process. We chose to develop our EDA with EventBridge. But before doing that we started out way different.
First, we didn't use an EDA at all. After growing and experiencing the downsides of that we started using message queues.
This helped a lot in terms of performance & asynchronous tasks but the tight coupling still was an issue. This is when we made the decision to go fully on EventBridge. One of the main benefits here is really to have less code for routing events.
The whole routing logic is defined in config. We don't want to query the database for simple tasks such as checking if a blog has gitHubBackup enabled if we have this data available already.
Final Words
I hope this post could shed some light on building an EDA on AWS. Like I said in the introduction these are not all ways out there.
This post is also highly motivated by Sam's and Danillos's talk about building event-driven architectures on AWS. You can find this talk in the Resources section.
Hashnode is keen on building amazing architecture to serve its customers best. To fully understand our process the next post will be on an introduction in EventBridge in more detail.
✌️
Resources
AWS re:Invent 2021 - Building next-gen applications with event-driven architectures
The Many Meanings of Event-Driven Architecture • Martin Fowler • GOTO 2017
I Build Applications - Event-driven Architecture (Level 300)