





Table of contents
One of the downsides of our recent growth was an increase in spam. Since we all hate spam, and it was diluting the quality of content, we started cleaning up manually. But soon we realised that it wouldn't scale, and we ended up wasting an hour or so every day cleaning spam. So, one day while having a casual conversation with my co-founder Fazle, he asked me if we could automate it somehow. Because of our manual efforts, we had generated a lot of historical data with respect to spam classification. "Can you feed that data and train an ML model?", asked Fazle. I thought it was an excellent idea to take the help of AI to automate the process and save us more time.
I am a big fan of no-code tools and off-the-shelf APIs. After all, I want to utilise my time to solve business problems and not reinvent the wheel. That's the reason we migrated to MongoDB Atlas last December instead of hosting a DB on premise. And because of the same reason we decided to use Vercel, instead of doing things manually on AWS or DigitalOcean. So, after a quick research, I decided to give Google's Vertex AI a try! Because that seemed like the easiest option.
Google's Vertex AI has a lot of use cases. One of them is text classification. So, once you have trained your model with sufficient data, it can accurately predict the label for a piece of text. That's exactly what we needed.
Preparing dataset
The first step is preparing data. We decided to extract 10K posts from our DB (5K spam, and 5K normal), and create the dataset. Google expects you to format your content in .jsonl format. It simply means each line in your file is a JSON object. Here's what it looks like:
posts.jsonl
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "Nhu cau su dung dich vu cho thue xe 29 cho tai Ha Noi", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "How to Get Online Assignment Help", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "Facebook Shops: A Sure Way To Grow Your Ecommerce Business", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "https://secretland.xyz", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "Recognize! 7 habits that will make acne sticky about the face", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "How to choose the right Payment Gateway?", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
{ "classificationAnnotation": { "displayName": "spam" }, "textContent": "How Can AI Make Us Smarter - Future of Education?", "dataItemResourceLabels": { "aiplatform.googleapis.com/ml_use": "training|test|validation" } }
...
We are trying to detect spam based on post title. displayName property is our label. The AI will parse our file, and use this label to categorise the existing dataset. After we uploaded the dataset, Vertex categorised the post titles properly as expected.
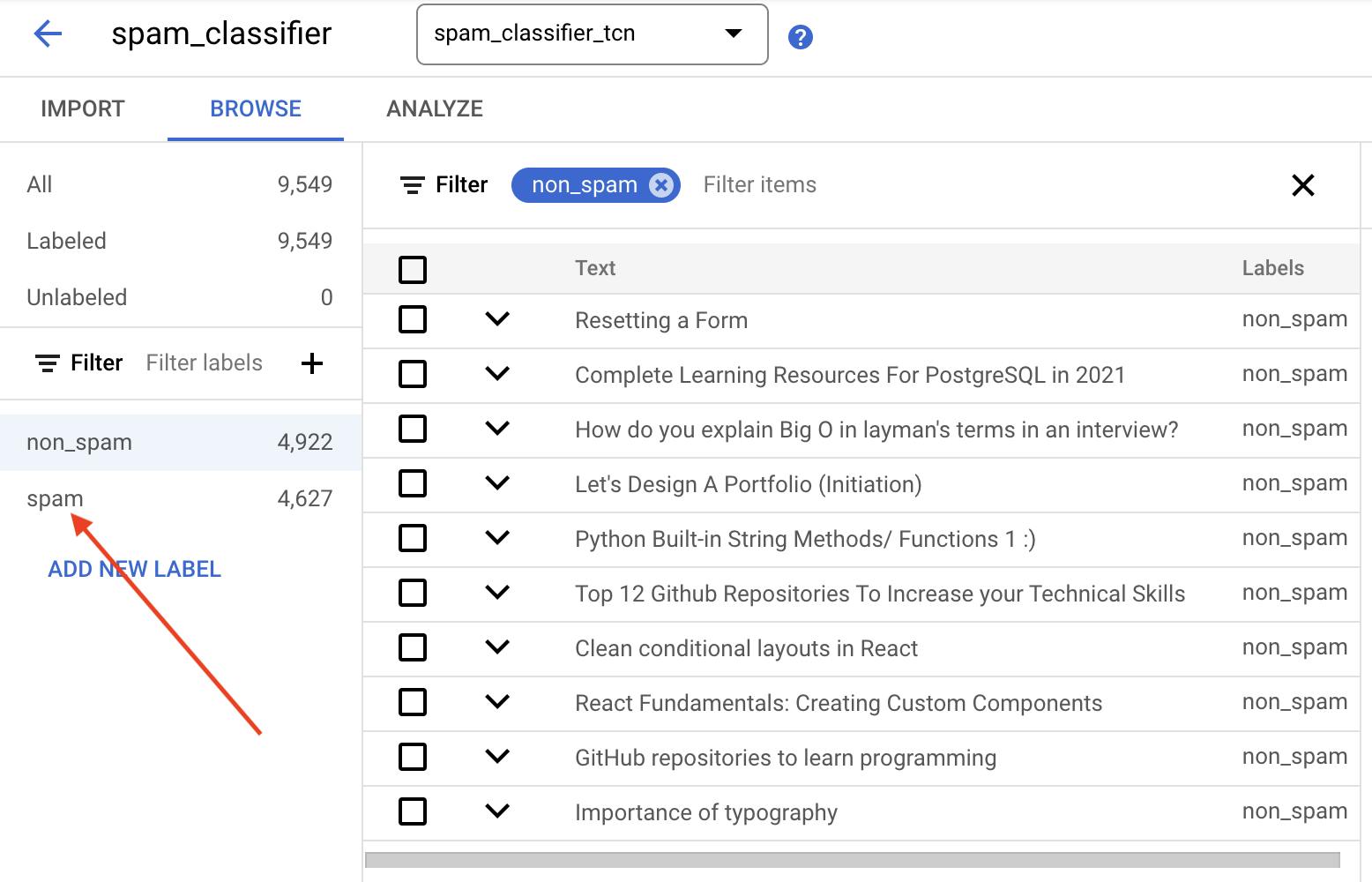
Train the Model
The next step is training the model. It took ~6 hours for Vertex to train the model. After the training was done, we saw the following result:
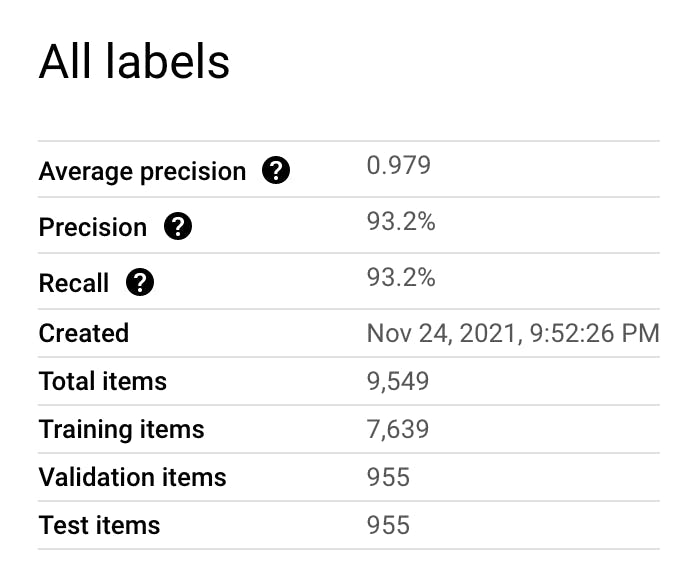
As you may note, 90% of the titles were used for training, and 10% were used for predicting the label. The accuracy was ~93%, which was pretty useful for our use-case. So, we decided to deploy the model and test it out.
Deploy and test
Once you deploy the model, you will get an HTTP endpoint to make requests. You can call it from terminal like the following:
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/ui/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d '{
"instances": {
"mimeType": "text/plain",
"content": "YOUR_TEXT_CONTENT"
}
}'
If you just want to test, you can also do so from Vertex dashboard. For serious applications, you might want to use Google's SDK. For example, we use Google's Node.js SDK to examine post titles every time a new post is published on our platform. Since your access token expires in an hour, you need to take care of the following in order to use the SDK from your Node.js app.
- Generate a service account, and give it access to Vertex.
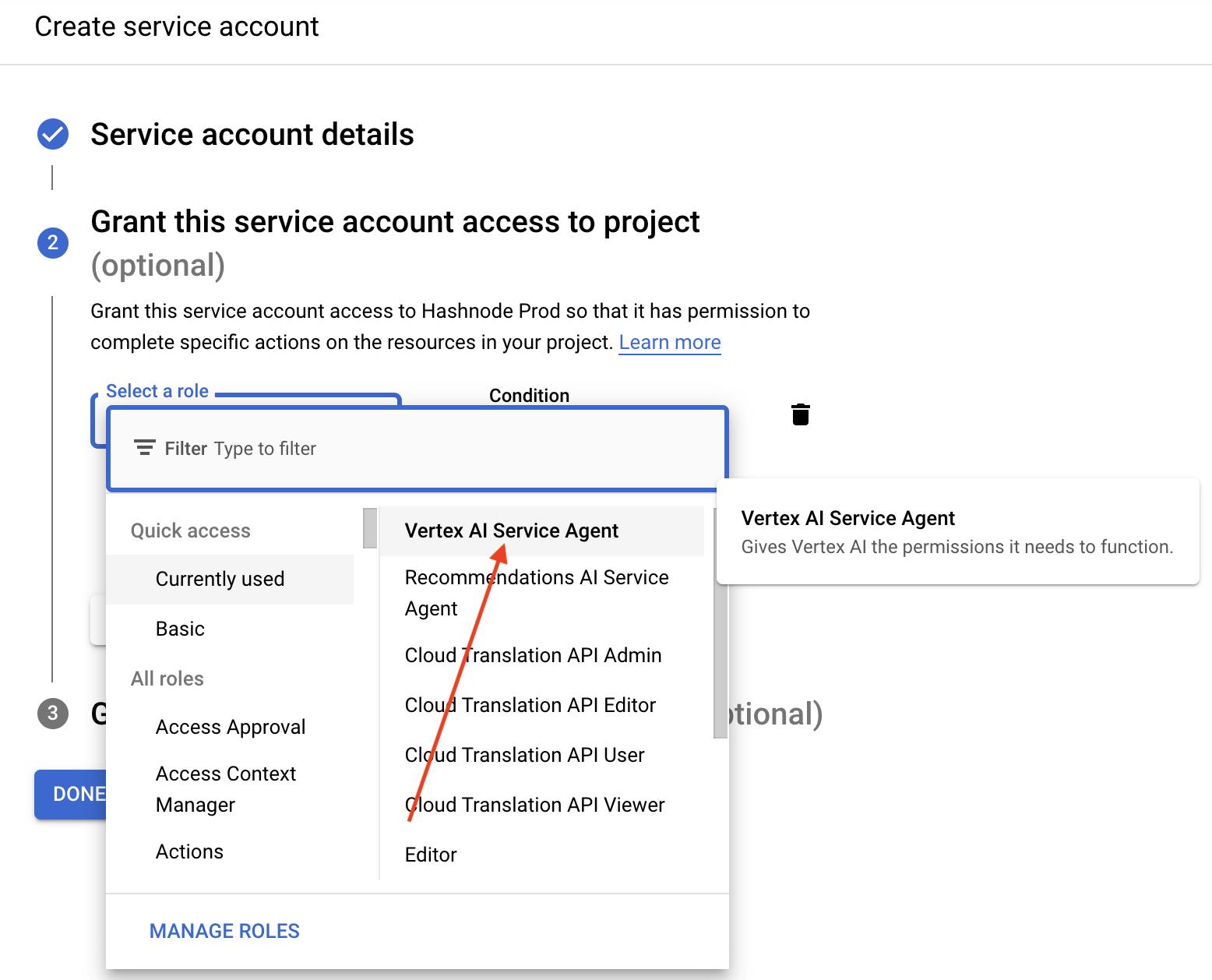
After creating, download the
jsonfile containing your service account keySet
process.env.GOOGLE_APPLICATION_CREDENTIALSto the path of thejsonfile.
I struggled a bit here as I don't have much experience using Google services. If you are facing auth issues, make sure to follow the above steps.
The accuracy is amazing. It automatically detects spam content, hides them from Hashnode, and pings us on discord. In the initial few days, we used to observe discord for any anomaly. We did notice a few false positives, but after tuning the confidence level, it has been working pretty well.
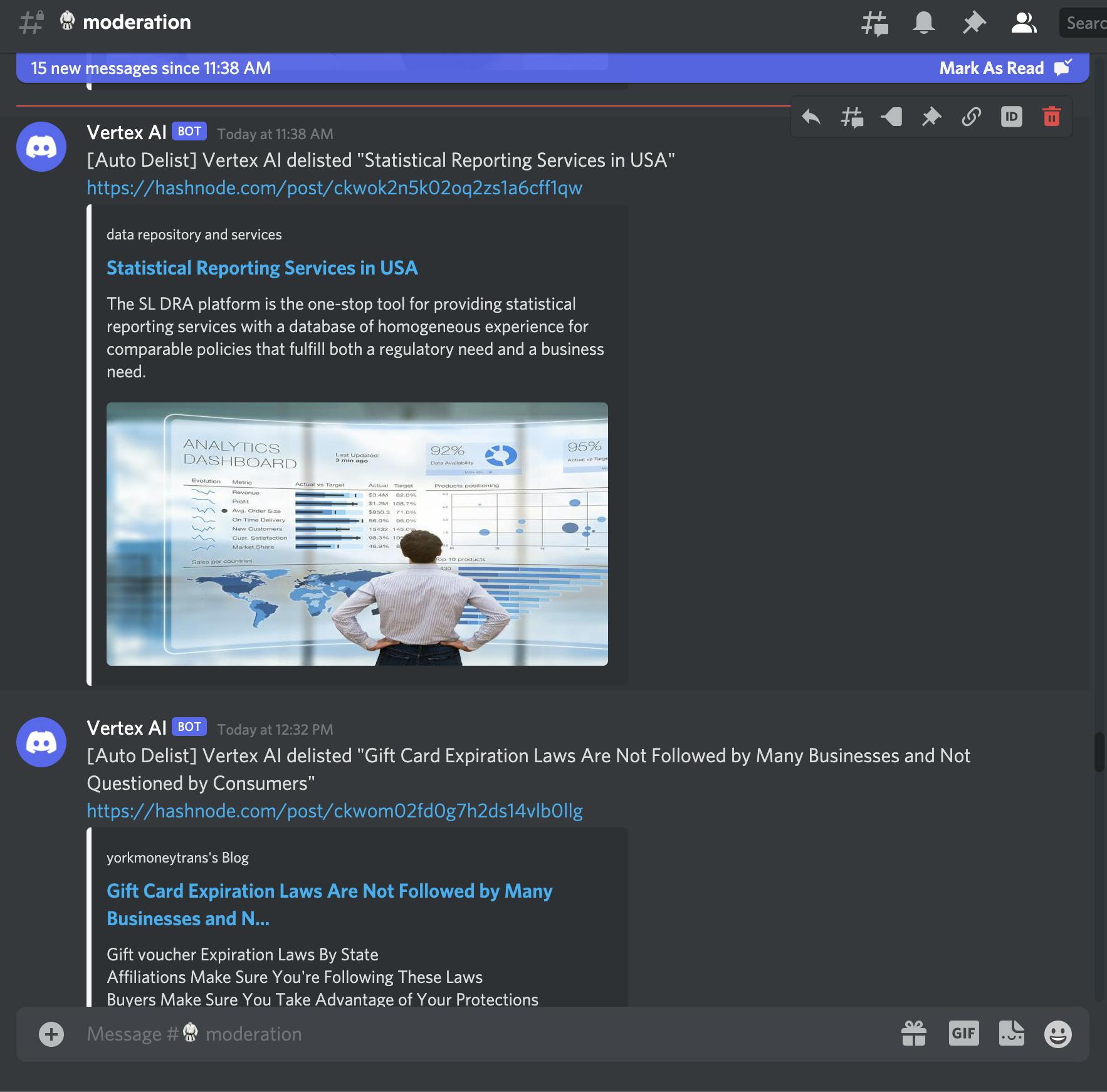
So, spam clean up is pretty much on autopilot these days. It saves us time, and we can channelize our efforts where it matters the most. This is one of the reasons why I am such a big advocate of hosted APIs. It would have taken us a few days to implement this on our own. By using Vertex, we went from preparing the dataset to getting accurate predictions within several hours.
Did you build something similar that helped you save hours of your time? I would love to know your experience. 🙌