


How We Send Mass Personalised Emails using AWS Serverless Technologies?
Here's how we solved some of the challenges of sending hundreds of thousands of personalized emails every week using AWS serverless technologies.


Table of contents
As a Hashnode user, you will most likely already have received an email from us. I am sure you can imagine that we are sending quite a lot of emails every week – and most of them are personalized and you are the only one receiving exactly that email. But how do we do that and what challenges did we have to overcome doing all of that using serverless technologies on AWS? That is what this post will be about.
I won't be writing all the code for the solutions here. I will focus on concepts and architecture in this post. You should get an idea of the thought process rather than the exact implementation.
Context
Before we'll get to the challenges and their respective solutions, we need to know the context because some parts of the infrastructure are given and can't just be easily replaced. Therefore the context defines the boundary for the possible solutions.
We use AWS for our backend services and we try to be "as serverless as possible" (yes, it is a spectrum, not just serverless vs. not-serverless). For our data storage, we use MongoDB Atlas. We send emails via SparkPost. We are also using SES – we plan on consolidating that in the future. Though the used email service is not that important here because the challenges apply similarly for all services.
You can read more about how we are leveraging serverless AWS technologies in How We Build Serverless Audio Blogs with AWS on a Scale and How We Leverage Serverless for Backing up Your Posts.
Example Email
Let us talk about a more concrete example in order to be able to better understand the challenges and possible solutions we will be talking about next.
New Followers Weekly
We send out a personalized email informing you about new followers within the last week – at least if you have not deactivated that email notification (you can manage your email settings).
This is what mine looked like last week:
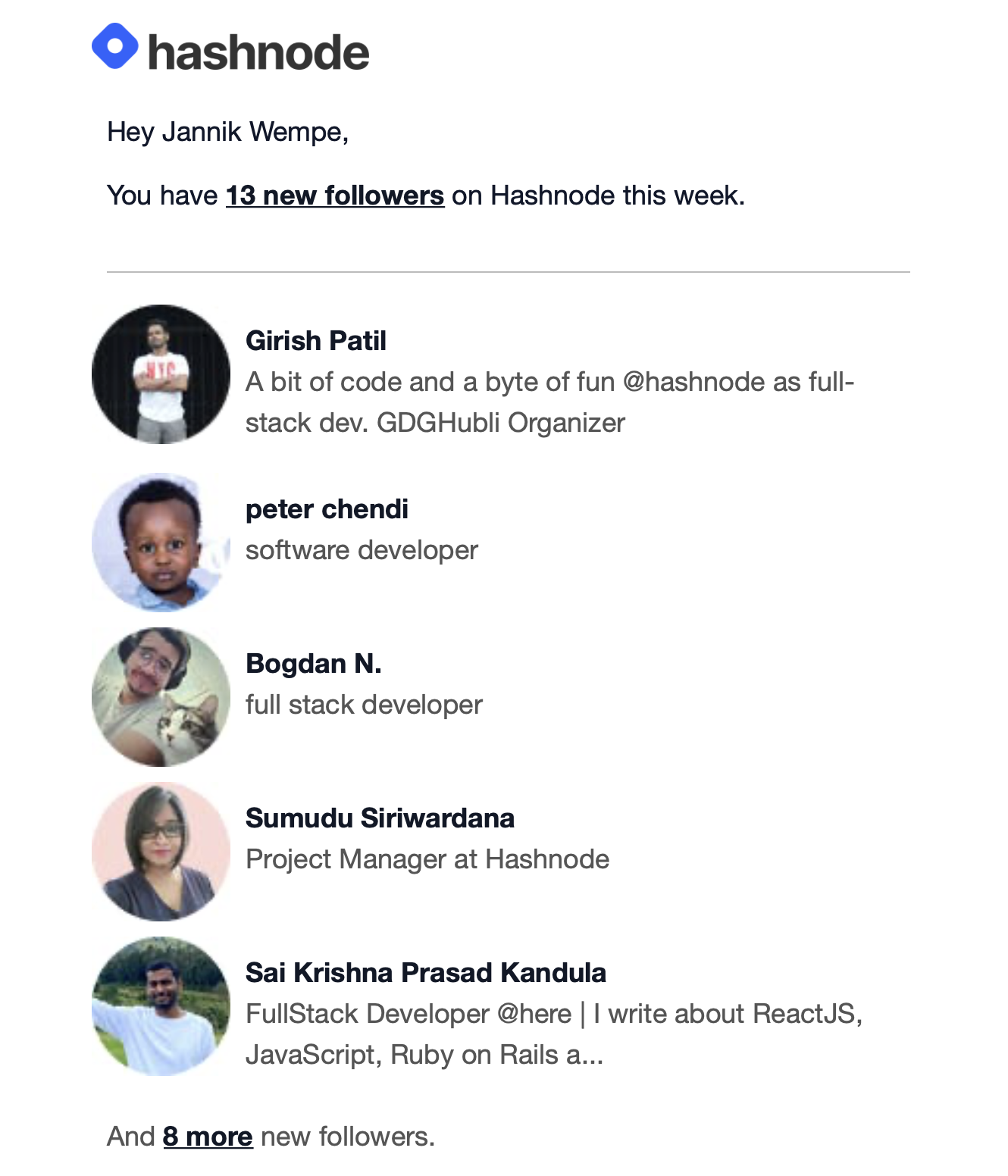
BTW: Thanks for following 😉
Let us assume we send 100k of this email every Wednesday at 13:00 UTC.
Basic Architecture
In this section, I will quickly walk you through the basic architecture we are using for sending the aforementioned email. It is slightly simplified for the Email Sending section because we also can send email via SES, which is out of scope here. I will not go into detail since this is not the focus of this post. This is not the final architecture. We will extend it later for one solution to a challenge we had. This is what it looks like:
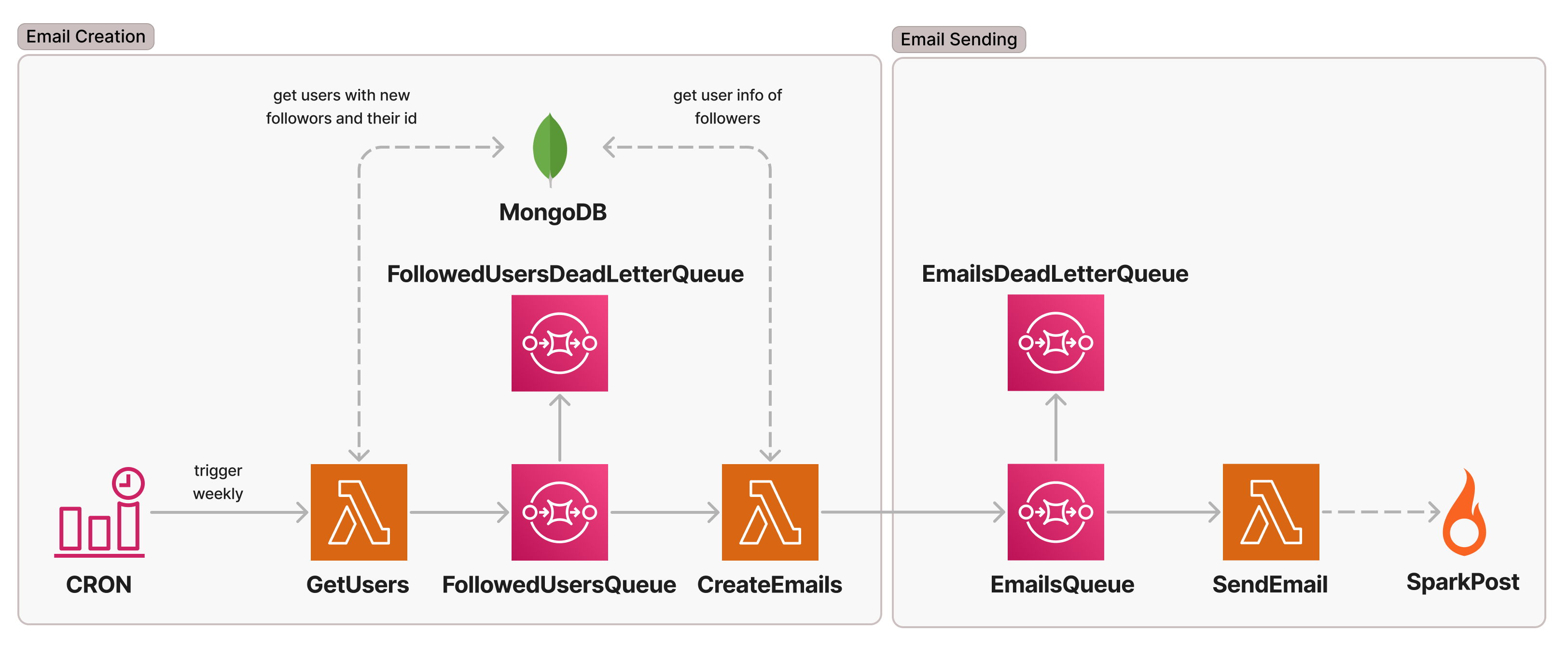
An EventBridge Rule CRON is triggering the weekly email flow by invoking the GetUsers Lambda which collects all the users with new followers within the last week and publishes these as individual messages (sent in batches) to the FollowedUsersQueue. We use SQS queues with dead-letter queues between Lambdas in order to be able to adjust throughputs and to be able to easily retry messages if their processing fails. CreateEmails consumes the messages and fetches additional information required for the creation of the email from MongoDB. It then again publishes the email data in another EmailsQueue where a SendEmail Lambda will pick them up and send them out via SparkPost.
Challenges and their Solutions
Okay, let us get into it. Which challenges exist and how can we tackle them?
Exhausting MongoDB Connections
As we are focusing on serverless AWS services, Lambda is our first choice for compute-related workloads. Lambda can scale horizontally (multiple Lambda running parallel) very quickly. That can become a threat for databases that have a limited pool of connections. We have to make sure to not exhaust all connections because that would impact the rest of Hashnode using the same database.
Solution 1
Due to the aforementioned reasons and because creating new database connections via TCP (Transmission Control Protocol; a protocol of the network layer) over and over again is slow, a lot of databases offer solutions dealing with connections for you. They often provide an HTTP(S) endpoint.
You can send your database request to that endpoint and they manage the connections to the database for you. The MongoDB Atlas Data API does exactly that. It just became Generally Available (GA) on the 7th of June. (This is why we are not using it yet, but we will check it out soon.) With something like the MongoDB Atlas Data API we have one thing less to worry about (connections) BUT be aware that it also comes with a price of a slightly increased latency due to the additional step between our request origin and the database.
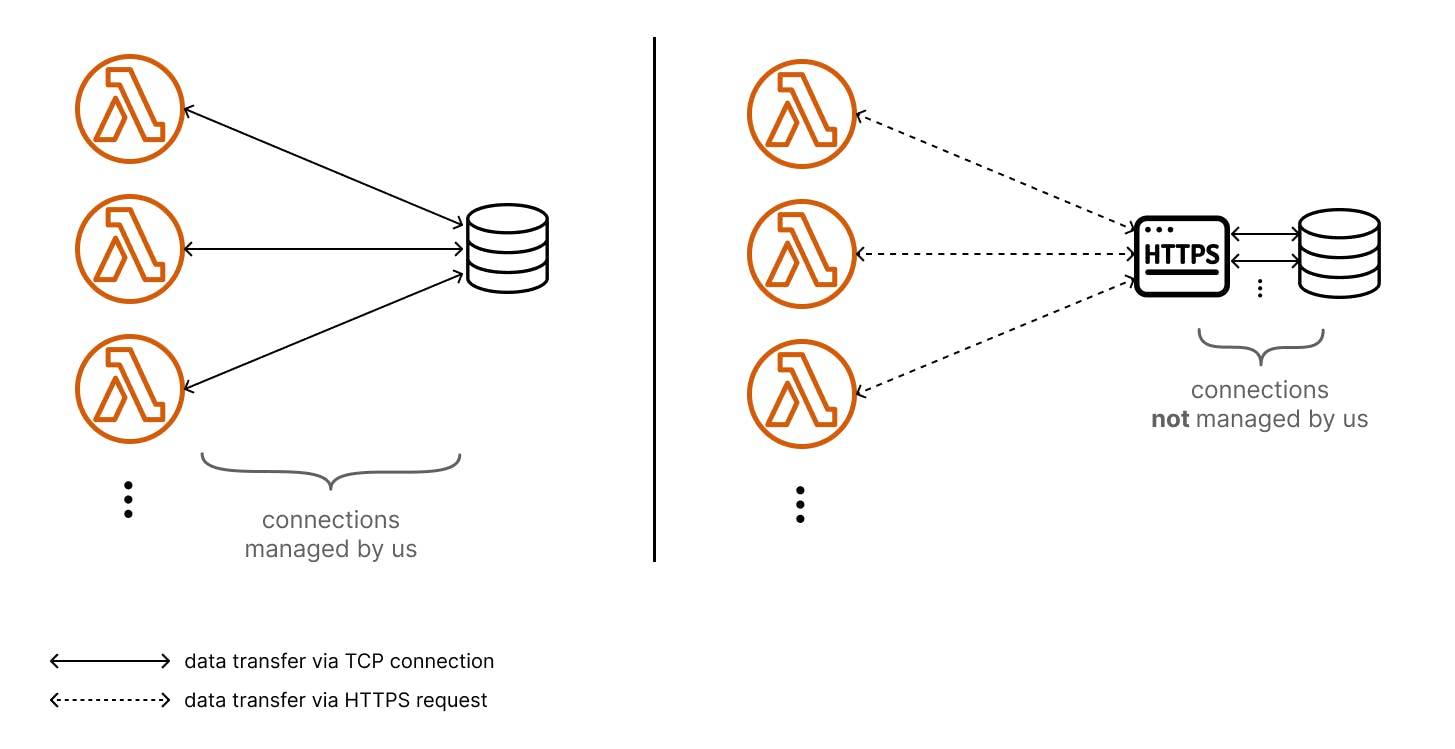
This also is how other services like Upstash (Redis via REST API) and Supabase (PostgreSQL via PostgREST) work.
As mentioned, we are currently not using this approach (but we will investigate and maybe switch some use cases). We are currently using the next proposed solution.
Solution 2
We limit the database connections being opened by CreateEmails (GetUsers only gets invoked once). We are doing this by a combination of multiple measures:
Firstly, we reuse database connections within a single Lambda execution context (subsequent invocation of the same Lambda processing your request). This can be done by following the best practice to create database connections outside of the Lambda handler.
Secondly, we limit the concurrency of Lambdas by setting ReservedConcurrentExecutions: 5. This way there will be no more than five parallel executions of CreateEmails.
Note that Lambda polls SQS with five parallel connections in the beginning (this is unrelated to ReservedConcurrentExecutions!). The five polling connections will at least invoke the Lambda each if there are enough messages. Therefore throttling can occur with ReservedConcurrentExecutions < 5 and five polling connections trying to invoke the Lambda each (more than five invocations). This is from the AWS docs: Using Lambda with Amazon SQS:
If you configure reserved concurrency on your function, set a minimum of five concurrent executions to reduce the chance of throttling errors when Lambda invokes your function.
Thirdly, we are using the mongodb MongoClient. That client is instantiated with a maxPoolSize option. From the MongoDB docs:
The maximum number of connections in the connection pool. The default value is
100.
So, without specifying maxPoolSize each Lambda will create up to 100 connections.
This is how you can calculate the maximum number of connections being created by your Lambda invocations:
ReservedConcurrentExecutions * maxPoolSize <= total number of connections
Note: There is also MongoDB Atlas Serverless which is serverless itself and it makes it easier to be used with AWS Lambda. We won't switch our database (yet?). Therefore this is currently not an option for us but maybe it is for you.
Exhausting MongoDB CPU
Besides exhausting the connection pool of MongoDB we could also run into issues exhausting the resources of the MongoDB instances (e.g. CPU). By limiting the connections we are already indirectly limiting CPU usage because it limits the parallel queries being made. But there is another important measurement we could apply to reduce the CPU usage of each individual query.
Solution
Make sure your MongoDB queries are covered by indexes.
Consider adding one or more indexes to improve query performance.
Is mentioned in the MongoDB Fix CPU Usage Issues docs.
Too Many Emails in a Short Period of Time
There are two potential issues with sending a huge amount of emails in a very short period of time:
Firstly, the email service could throttle (this is not the case with SparkPost transmission API). We (kind of) already deal with it because messages will be retried if their processing failed.
Secondly, we don't want to be considered a spammy email sender because we send a burst of emails. This is something we are concerned about. For this reason, we want to stretch the time frame in which the emails are sent.
Solution
We can limit the emails being sent within a time frame by the SendEmail Lambda by making use of the already existing EmailsQueue to limit the throughput.
We can adjust the throughput by tweaking the BatchSize for the Lamba SQS Event Source. A lower BatchSize results in fewer messages being picked up by SendEmail from EmailsQueue. We can combine that with limiting the ReservedConcurrentExecutions of the Lambda itself (like we did forCreateEmails to deal with MongoDB connections).
This is an example of how you can roughly calculate the time it takes to send out all emails (100k in our case). I will explain it afterward:
// Inputs
total emails = 100000
ReservedConcurrentExecutions = 5
BatchSize = 3
time between Lambda invocations = 0.1s // can highly vary
avg. Lambda execution time = 0.5s // can highly vary
total parallel Lambda invocations
= total emails / (ReservedConcurrentExecutions * BatchSize)
= 100000 / (5 * 3)
= 6666.66
total time sending all emails in seconds
= total parallel Lambda invocations * Lambda execution time + total parallel Lambda invocations * time between Lambda invocations
= 6666.66 * 0.5s + 6666.66 * 0.1s
ReservedConcurrentExecutions * BatchSize * Lambda execution time`
= 4000s
= ~67min // ⚠️ highly depends on varying inputs
Probably the first thing you asked yourself is what it this time between Lambda invocations is about? There is some time between Lambda invocations (even within the same execution context). The 0.1s is just a very rough estimation. I have seen values between 0.02s and 0.7s. The number seems small but with the number of total invocations, it is something that can drastically change the overall required time. The same holds true for the average Lambda execution time which is the time the Lambda needs to send the email. This time will also vary. For these reasons, the end result is a very rough estimation.
Even though the outcome can vary, this solution can be good enough to restrict the number of emails being sent out within a given time frame.
There are way more accurate solutions (e.g. using Step Functions with custom Wait tasks for processing batches) but they introduce more complexity. As always: it is a trade-off.
Sending Email Exactly Once
This is one of the most important ones. We don't want to send the same email twice to a user. We also have to make sure that we can retry messages without re-sending emails that already have been sent.
We extensively make use of SQS but SQS only guarantees an at-least-once delivery of messages:
[...] you might get that message copy again when you receive messages. Design your applications to be idempotent (they should not be affected adversely when processing the same message more than once).
The AWS docs suggest designing our application idempotent which means that subsequent processing of the same input yields the same result. If that is the case, it is no issue to receive a message more than once because it would produce the same outcome. Well, that is easier said than done when sending emails via an external API. But we have found a solution.
Solution
We use DynamoDB (DDB) to keep track of the messages that have been processed by the EmailSender. This is what the final infrastructure looks like:
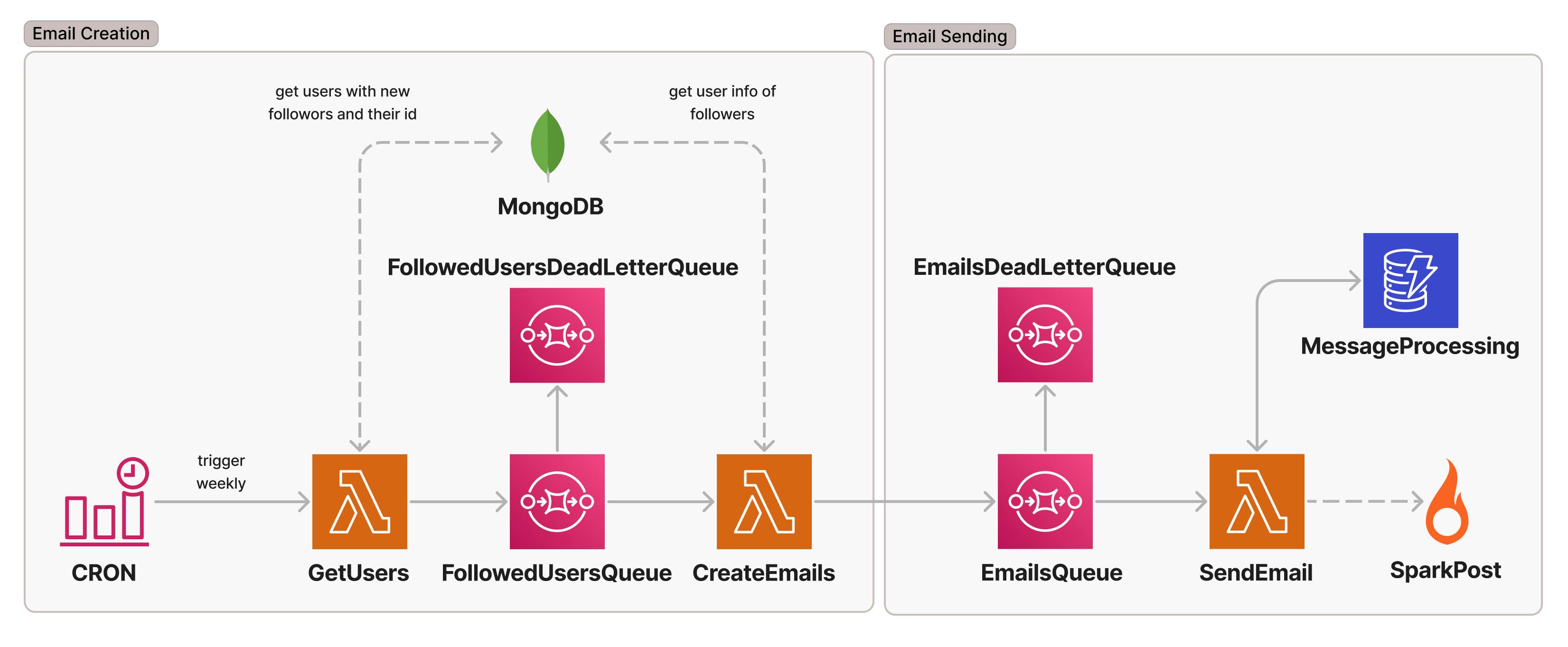
We could store something that uniquely identifies the message being processed and update the item once the processing has been done successfully. Then we would check the DDB item before starting any processing.
Do not use the messageId for that unique identifier! By using the messageId you can't just re-run the whole email sending flow (by invoking GetUsers) and only re-process the not-yet processed messages. The messages would have new messageIds and the same email can be sent out again. We use the email recipients userId which uniquely identifies an email to be sent.
This is what the flow could look like:
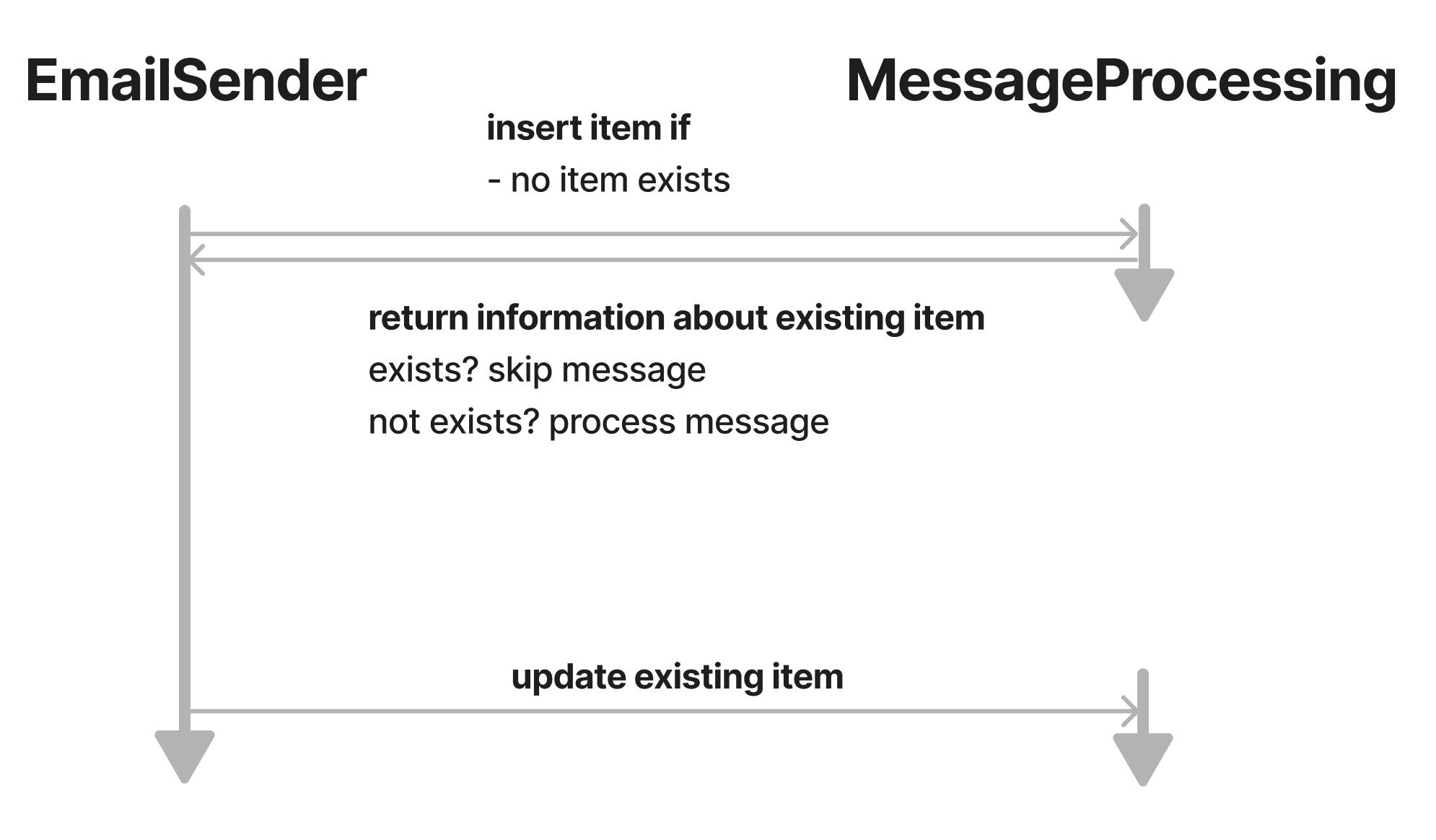
The data structure we are using is this:
interface IdempotencyItem extends IdempotencyItemKey {
/** Partition Key (PK) that uniquely identifies a message. */
idempotencyId: string;
/** Timestamp indicating when the processing has been started. */
startedAt: number;
/** Timestamp being set once the message processing is done. */
completedAt?: number;
/** UTC date for the last time the item has been changed. */
updatedAt: string;
/** Automatically deletes an item once TTL is over. */
ttl: number;
}
With DDB we can indirectly do basic reads on a write operation by using a ConditionExpression. If the condition fails, the write operation fails and returns a ConditionalCheckFailedException error code. So we could check for an existing item by using ConditionExpression: 'attribute_not_exists(idempotencyId)'. If the condition fails that means that there already is an item with the provided idempotencyId. Therefore this message is either currently being processed or already has been processed.
Do not use a separate read and write for this! If you do this, two parallel Lambda executions read from the database, finding no item and both writing and entry and start the processing. You will end up with race conditions.
At the very end of the processing, we'll update the item indicating that it has been processed by setting completedAt.
Dealing with message retries
Well, there is an important piece we are missing here. The outlined flow would prevent us from retrying failed messages. Imagine the processing fails between the DDB writes. There would be an entry from the initial write and a subsequent retry of a failed message would skip processing because there already is an item for that idempotencyId:

So, how can we adjust the flow in order to enable retries? We need another ConditionExpression. We know that a Lambda takes at maximum the Lambda Timeout duration for processing because then the execution would be stopped. Also, we have set the SQS VisibilityTimeout to a value higher than the Lambda Timeout (which you should do, otherwise you will often process the same message). If there is an error during Lambda execution the message will be sent back to the queue and the next time it will be processed at least the VisibilityTimeout has passed. Therefore we can assume that there was an error if thestartedAt is longer ago than the VisibilityTimeout duration is. This is is an excerpt of our code showing the PutItemInput:
const putItemInput: DocumentClient.PutItemInput = {
TableName: tableName,
Item: {
idempotencyId,
startedAt: now.getTime(),
updatedAt: now.toISOString(),
ttl: createTtlInMin(60 * 72)
}
// no startedAt -> first processing
// has startedAt, but a while ago -> retry
// no completedAt -> can't move from completed to started (should not occur, just for safety)
ConditionExpression: `(attribute_not_exists(#startedAt) OR #startedAt <= :startedAt) AND attribute_not_exists(#completedAt)`,
ExpressionAttributeNames: {
'#startedAt': 'startedAt',
'#completedAt': 'completedAt'
},
ExpressionAttributeValues: {
// if VisibilityTimeout duration (which is > Lambda Timeout) is not over, it can still be in process in another Lambda invocation
':startedAt': subtractSecondsFromEpoch(now, visiblityTimeoutInSeconds)
}
};
Note: It contains the actual code comments. My take: comments like this are very useful. It is not always possible/useful to try to express everything through variable- / function-names (even though it should in most cases!).
subtractSecondsFromEpoch(now, visiblityTimeoutInSeconds) subtracts visiblityTimeoutInSeconds (which is provided by an environment variable) from now. If this value is smaller than the startedAt of the existing item (checked by #startedAt <= :startedAt), it is indicating that the VisibilityTimeout has not passed and it is not safe to reprocess the message. It should be skipped. This is the final flow:
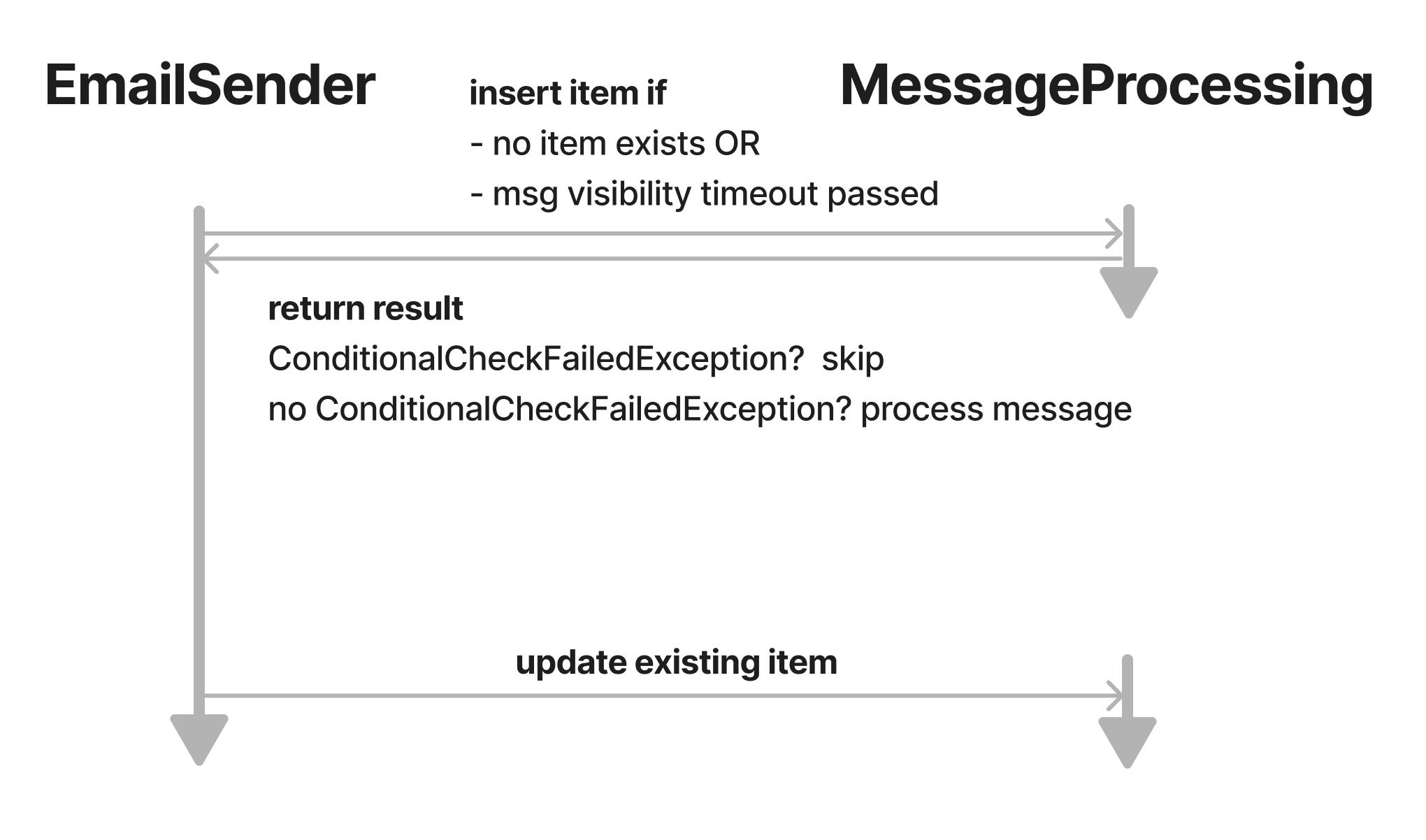
With these conditions, it is safe to reprocess messages and to start the whole email sending flow as often as you like within the provided ttl (the will be removed after that). The handler is now idempotent regarding the email sending.
Besides this flow, we also only return failed messages of a batch back to SQS by utilizing ReportBatchItemFailures. This is not necessary for the flow to work, but it is a nice optimization. Therefore I won't explain it in detail here.
(Potentially) Too Large Email Data for SQS Messages
We are publishing messages containing the data required for the email to the EmailsQueue. An SQS message has a message size limit of 256kb. Therefore, we could run into issues with emails requiring a lot of data. This is currently not the case (and we don't expect it to be an issue in the near future) but it is still a good thing to have a potential solution for that in mind.
Solution
Instead of passing the email data in the message body, we could save it to S3 or DynamoDB and just pass the reference in the message. The EmailSender could pick up the data from the referenced source.
Conclusion
This was a lot! It is not always straightforward to implement features like email sending. There are often a lot of considerations (like dealing with external databases, idempotency and retries). We have to keep edge cases (like errors – which are hopefully edge cases 😉) in mind when implementing a solution.
Hopefully, this post gave you an insight into how we can identify challenges and find solutions for them. Let me know if you have any questions or considerations.