

CI Checks: Ensuring Better Code Quality and Faster Deployment
Strategies for Optimising CI Checks for Quicker Deployment and Improved Code Quality


How can you consistently deliver high-quality code that adheres to established coding guidelines and is free from errors?
The solution lies in implementing tests and multiple checks for linting and type errors.
This may seem straightforward, but it requires some adjustments to smooth out the developer experience (DX) flow and maintain developer productivity.
In this article, we'll explore how Hashnode previously managed its development workflow and the improvements it made to ensure better code quality and faster deployment through CI checks.
Goal
The goal is to establish a rapid feedback loop for developers, allowing them the freedom to experiment and move fast without being burdened by coding guidelines and the like.
Of course, we still aim to enforce coding guidelines and ensure that whatever reaches production is error-free and passes all checks. However, we want to accomplish this without hindering developer productivity and utilize tools at our disposal.
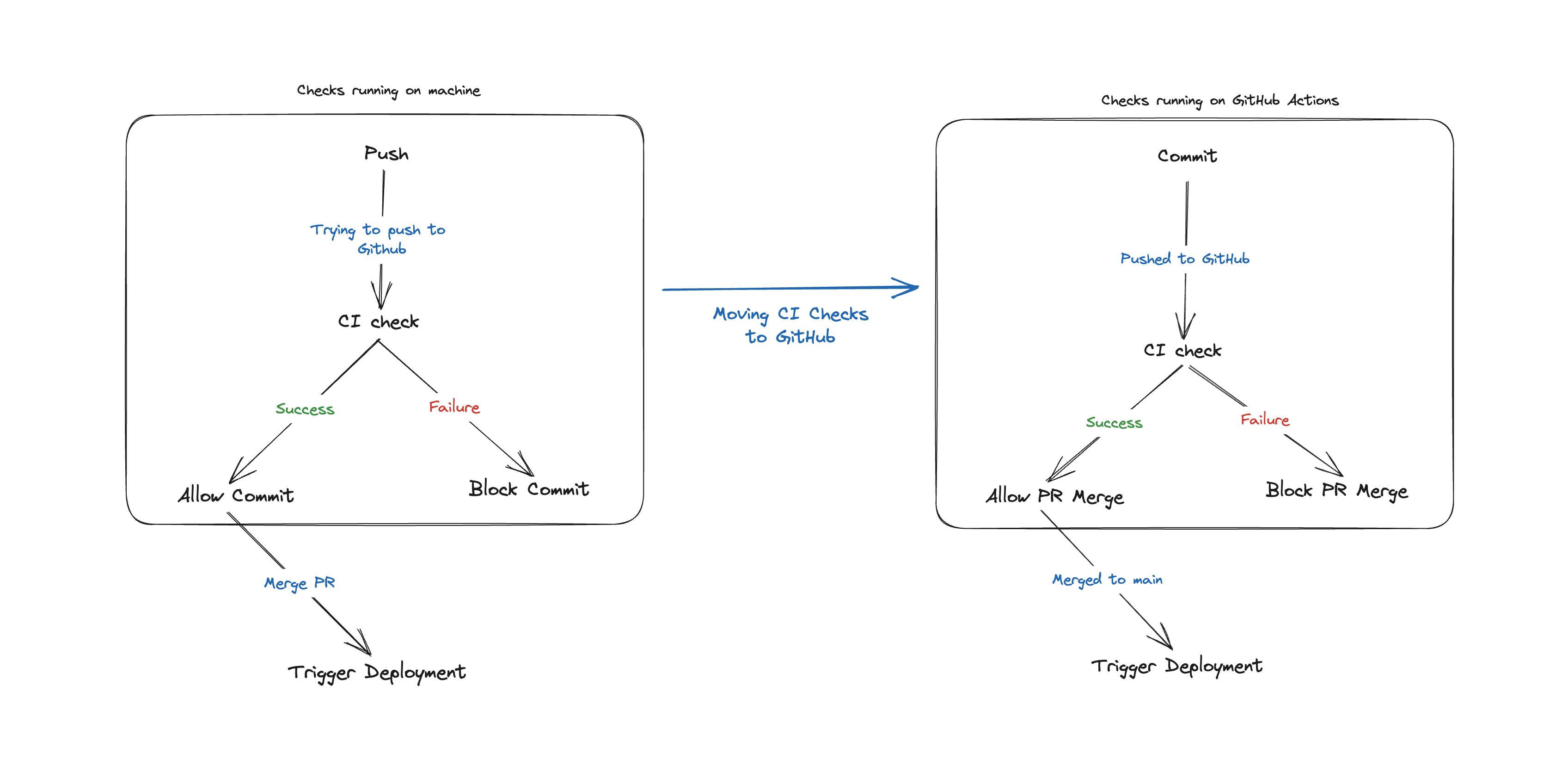
Previous Workflow
The previous workflow involved running each check on the developer's machine before they commit using pre-commit hooks. This involved enforcing coding guidelines, format commit messages and a bunch of other checks.
These guidelines were necessary but enforcing them at the pre-commit level was not a great idea. Developers should be allowed to code how they want and this was hurting the productivity.
Let's take a look at the different checks we had at the commit level.
Type Checks
We use TypeScript heavily to ensure the data types used in a codebase align with the expected types and catch potential errors or inconsistencies early in the development process. Usually, the IDE takes care of complaining whenever a certain function or component doesn't satisfy the types it was supposed to.
However, it is easy to overlook these warnings for pages that are out of the scope of the feature in development.
For this reason, it is necessary to perform type checks for every commit to guarantee that no issues arise throughout the codebase. This can be accomplished by using:
tsc --noEmit
This simple command will execute a type check on the entire codebase and generate an error if any issues are detected.
Linting
We use ESLint to enforce coding guidelines, ensuring that everything is in order. It also enforces aspects such as import order and accessibility checklists. To run lint checks on the relevant files, use the following command:
eslint . --fix --ext .js,.jsx,.ts,.tsx
These are plugins that we use at Hashnode
{
"eslint": "^7.24.0",
"eslint-config-airbnb": "^18.2.1",
"eslint-config-airbnb-base": "^14.2.1",
"eslint-config-next": "13.0.5",
"eslint-config-prettier": "^8.3.0",
"eslint-import-resolver-typescript": "^2.4.0",
"eslint-plugin-cypress": "^2.11.3",
"eslint-plugin-import": "^2.22.1",
"eslint-plugin-jsx-a11y": "^6.4.1",
"eslint-plugin-prettier": "^3.4.0",
"eslint-plugin-react": "^7.23.2",
"eslint-plugin-react-hooks": "^4.2.0",
"@typescript-eslint/eslint-plugin": "^5.39.0",
}
Tests
We use React Testing Library to write tests for all critical business flows. These tests run on GitHub Actions and report any issues if something is broken. We also have merge rules in place for pull requests, ensuring that only tested code is allowed to merge and proceed to production.
Husky
Husky is a pre-commit hook that ties everything together. We configured Husky to perform type checks and lint checks on every commit. This ensures that we only commit error-free code and block pushes if something is broken. Since tests take some time to run, we decided to keep tests at the CI level and not run them locally for every commit.
The Problem
All of this is excellent and has been working effectively; however, there was a problem. As the codebase began to expand, running all these checks took between 3 to 6 minutes. This negatively impacted the DX, as developers had to wait for all the checks to pass before they could commit any changes.
Having checks at the commit level also impacted the freedom to experiment without worrying about formatting guidelines or perfect type usage. Ultimately, what gets merged into production is what matters most.
If you're looking for arguments against pre-commit hooks, this serves as a good example.
Hashnode believes in moving fast and iterating rapidly but this was hurting our ability to move fast. We had to do something about it.
Let's take a look at how we improved our development workflow.
Optimizations to Speed Up Checks
We began considering ways to enhance our workflow, and several ideas emerged. One aspect we were certain about was the necessity to stop running these checks locally and transition everything to CI.
We need to take advantage of the tools at our disposal as much as we can and eliminate manual work. Let's talk about the improvements one at a time.
Moving Checks to CI
We already had a GitHub workflow in place for running tests on CI using GitHub actions; we expanded it to include type and lint checks.
We wanted to run these checks concurrently, so we utilized jobs within the workflow as a solution. This approach allowed us not to wait for one job to finish before starting another, enabling all three checks to run simultaneously. Let's examine the expanded workflow designed to execute these jobs concurrently.
name: PR Validation
on:
pull_request:
types: [opened, reopened, synchronize, ready_for_review]
branches:
- development
- main
jobs:
cypress-run:
if: github.event.pull_request.draft == false
runs-on: ubuntu-latest
env:
NODE_ENV: test
steps:
#...steps
type-check:
#...checkout repo and install dependencies
- name: Type checking
run: tsc --no-Emit
lint-check:
#...checkout repo and install dependencies
- name: Linting
run: eslint . --fix --ext .js,.jsx,.ts,.tsx
Now, we have three jobs running concurrently for tests, lint errors, and type errors.
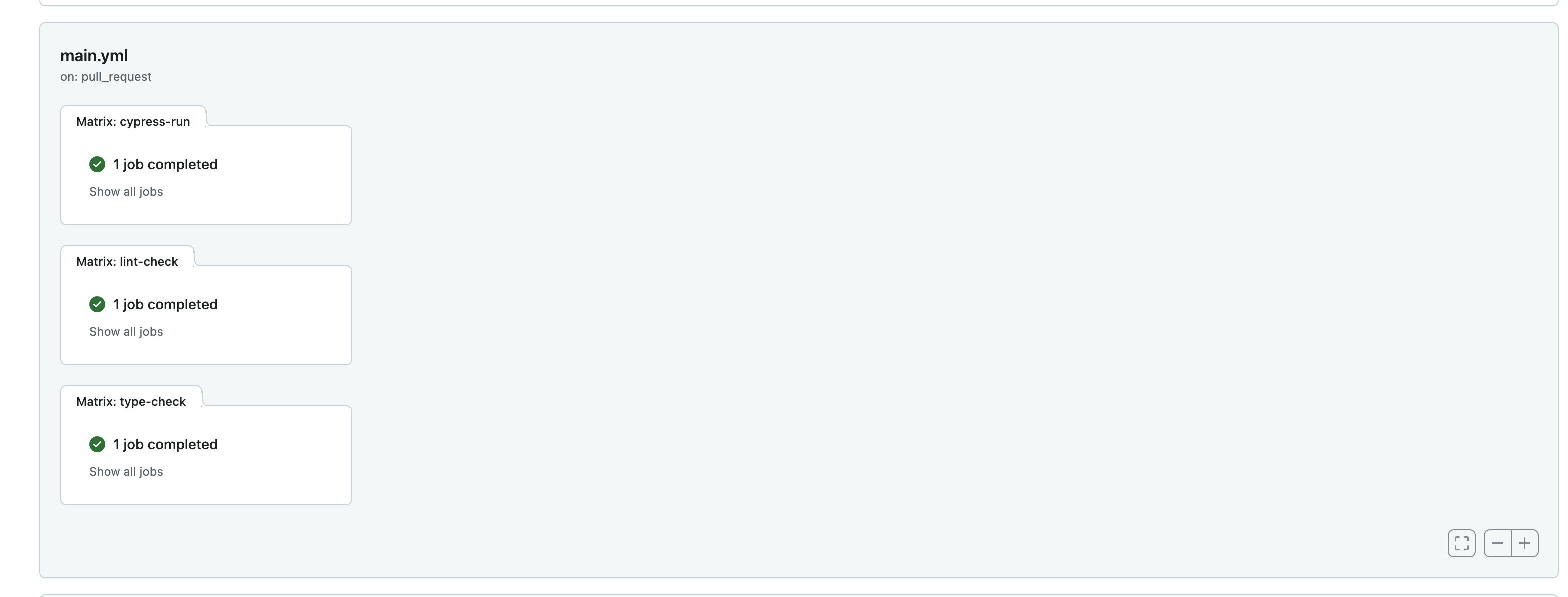
You might be wondering, what about catching errors during development to prevent pushing them in the first place?
Our IDEs are intelligent enough to detect these errors as we develop features, so we don't need to constantly check everything. The objective is to allow the merging of code only if it passes all checks in place, which can happen at the CI level.
After moving all the checks to the CI, we removed Husky and developers were allowed to push as they deemed appropriate. We will simply block the merging of pull requests if any issues arise.
This was an improvement over the previous approach, but we still have more work to do.
Machines running workflows are slower than our Macs, so checks performed on the CI are inevitably slower than when we run them locally.
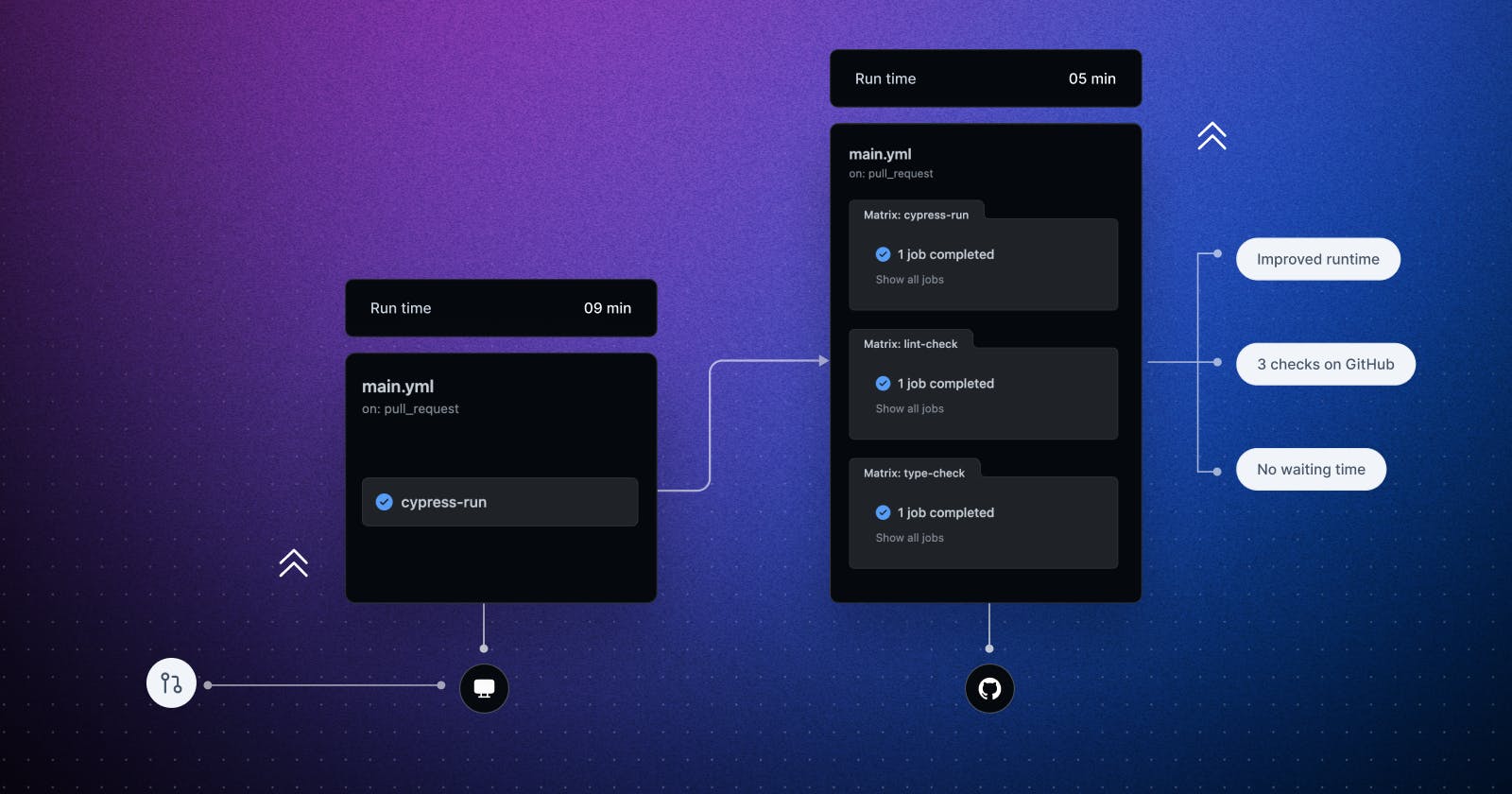
Running all three checks on the CI took between 9 and 12 minutes. This meant that developers had to wait for 9 to 12 minutes before they could merge their pull requests. There is certainly room for improvement in this workflow.
Lint Staged Files in GitHub Actions
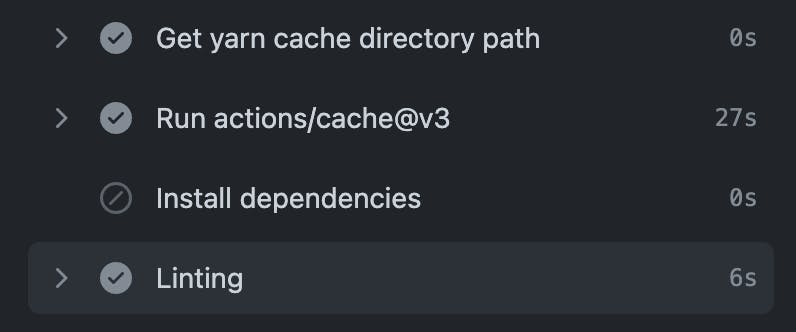
One quick improvement we could make is to run lint checks only for the files that have been changed, and that's where Lint-staged comes in handy.
Lint-staged typically works in conjunction with a pre-commit hook, such as Husky, to run lint checks on staged files only. However, we can modify it to run within a CI environment and focus solely on the files that have changed between commits. Let's replace the lint step in the workflow with this approach:
- name: Linting
run: yarn lint-staged --diff="origin/${GITHUB_BASE_REF}...origin/${GITHUB_HEAD_REF}" --no-stash
This command calculates the difference between your branch and the base branch and then runs ESLint on it. This minor adjustment reduced the lint check duration from 30 seconds to 6 seconds.
Skipping Library Check for TypeScript
Type checking, due to its nature, must run on the entire codebase, so there isn't much we can do to optimize it. However, we can skip the library check to make it slightly faster. To do this, replace the type check with the following:
- name: Type checking
run: tsc --pretty --skipLibCheck --noEmit
Now that we've improved all the checks individually, it's time to cache whatever we can. Let's see how to cache the installation of dependencies for each job.
Caching Node Modules
Since the three jobs run in parallel, they each need to install dependencies, which can be time-consuming. We've updated the workflow to cache dependencies and modified the "Installing dependency" step to skip when the cache is available. This can be achieved as follows:
- name: Get yarn cache directory path
id: yarn-cache-dir-path
run: echo "dir=$(yarn cache dir)" >> $GITHUB_OUTPUT
- uses: actions/cache@v3
id: yarn-cache
with:
path: |
**/node_modules
**/.eslintcache
${{ steps.yarn-cache-dir-path.outputs.dir }}
key: ${{ runner.os }}-yarn-${{ hashFiles('**/yarn.lock') }}
restore-keys: |
${{ runner.os }}-yarn-
- name: Install dependencies
if: steps.yarn-cache.outputs.cache-hit != 'true'
run: yarn install --frozen-lockfile
We include this for all jobs and retrieve node_modules from the cache when available. This significantly improved the time required to complete the entire check.
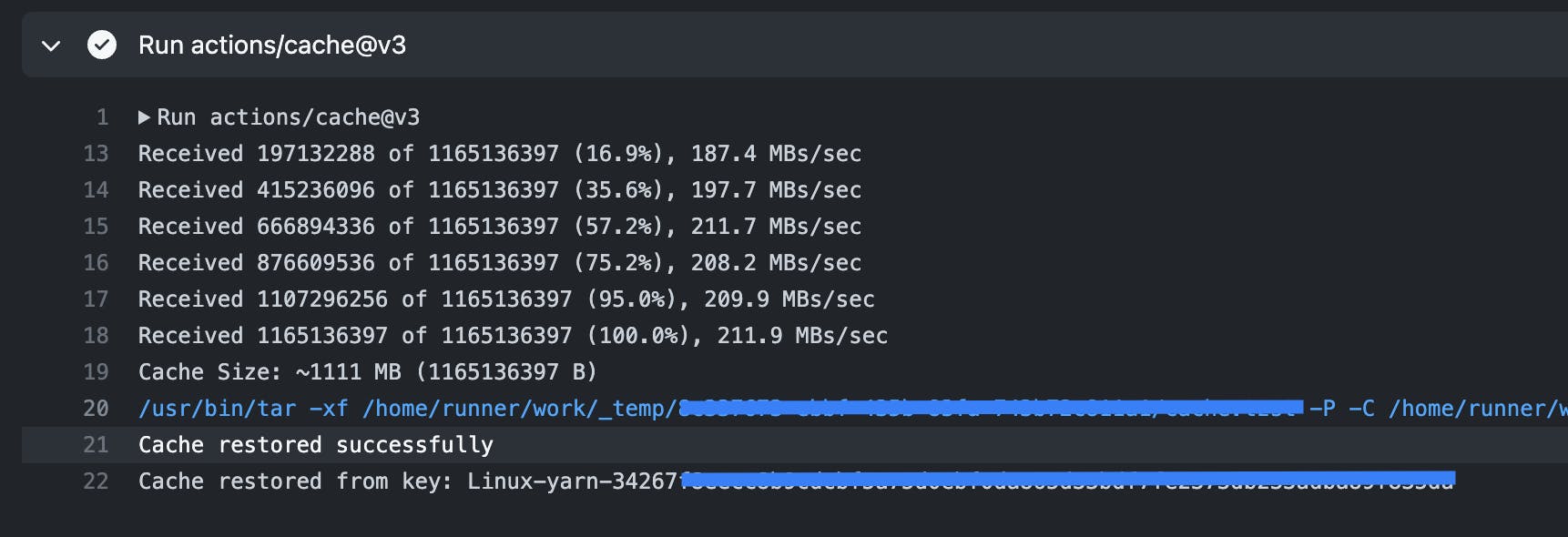
We are already in good shape, but there is one more improvement we can add.
Removing Checks from Vercel
Vercel builds typically perform linting and type error checks by default. This causes the entire build process to take approximately 8 minutes.
Since we already perform error checks on our end, there's no need to repeat them during builds. The final step is to bypass these checks in Vercel builds. We implemented this in vercel.config.js:
eslint: {
ignoreDuringBuilds: true,
},
typescript: {
ignoreBuildErrors: true,
},
You can check Vercel Docs for the config specification.

Conclusion
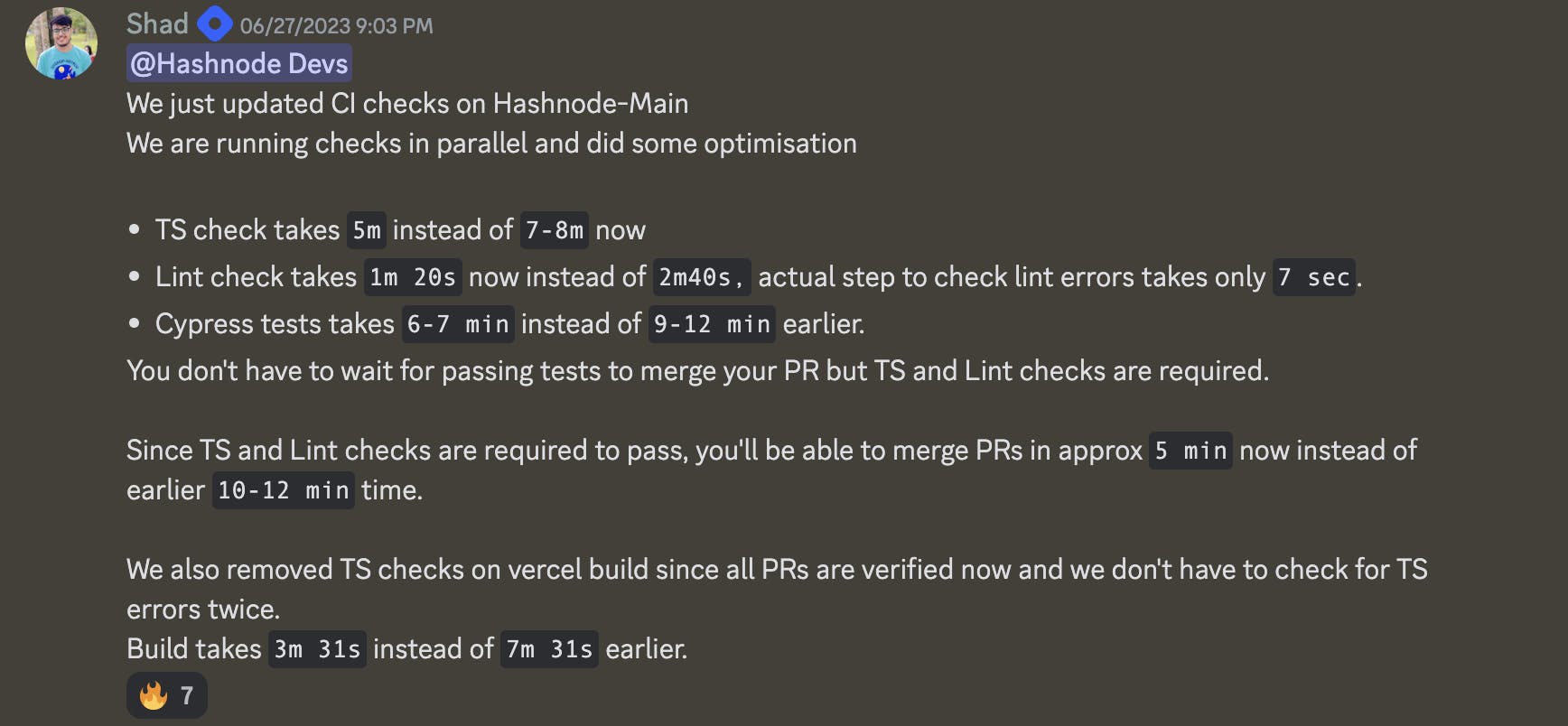
By adding all the necessary improvements we discussed above, we were able to reduce the time required to merge a pull request from 12 minutes to 5 minutes. This improved both the developer experience and the overall deployment process.
Here's the summary of the improvements we added:
I hope this article was informative and you learned something new today 😄.
Do you think we can improve it further? Let us know in the comments.