

The art of feed curating: Our approach to generating personalized feeds that match users' interests


Table of contents
- Why are personalized feeds such a big deal? 🤔
- Personalized feeds for different users – let’s see the result
- How to generate personalized feeds without machine learning?
- Which data is relevant for feed calculation?
- Ranking posts to generate personalized feeds
- How we keep your feed fresh all the time
- Next plans for the personalized feeds on hashnode
Feeds are an essential part of every social network. The same applies here at Hashnode. Until now, we have used a very basic and generic algorithm to generate feeds mainly based on hot ranking algorithms. Over time, we noticed that users struggle to find the content they are genuinely interested in on our platform. This is why we have decided to power up our feed game with personalized feeds 🎉
Why are personalized feeds such a big deal? 🤔
When you visit a community platform, you want to see content that speaks to you. That's where personalized feeds come in! Instead of a generic feed, personalized feeds focus on what the user finds interesting and valuable. They do this by looking at your past interactions, interests, and other factors to serve up content that's right up your alley 🎯
As a result, users get an enjoyable and engaging experience. Personalized feeds help to keep users happy and active by catering to their preferences and interests.
Let's explore how we implemented personalized feeds at Hashnode 🚀
Personalized feeds for different users – let’s see the result
Let's examine the concept of personalization. From a user's standpoint, assuming that the feed will differ for each individual is reasonable. When we query our feed endpoint for two distinct users, we obtain the following results:
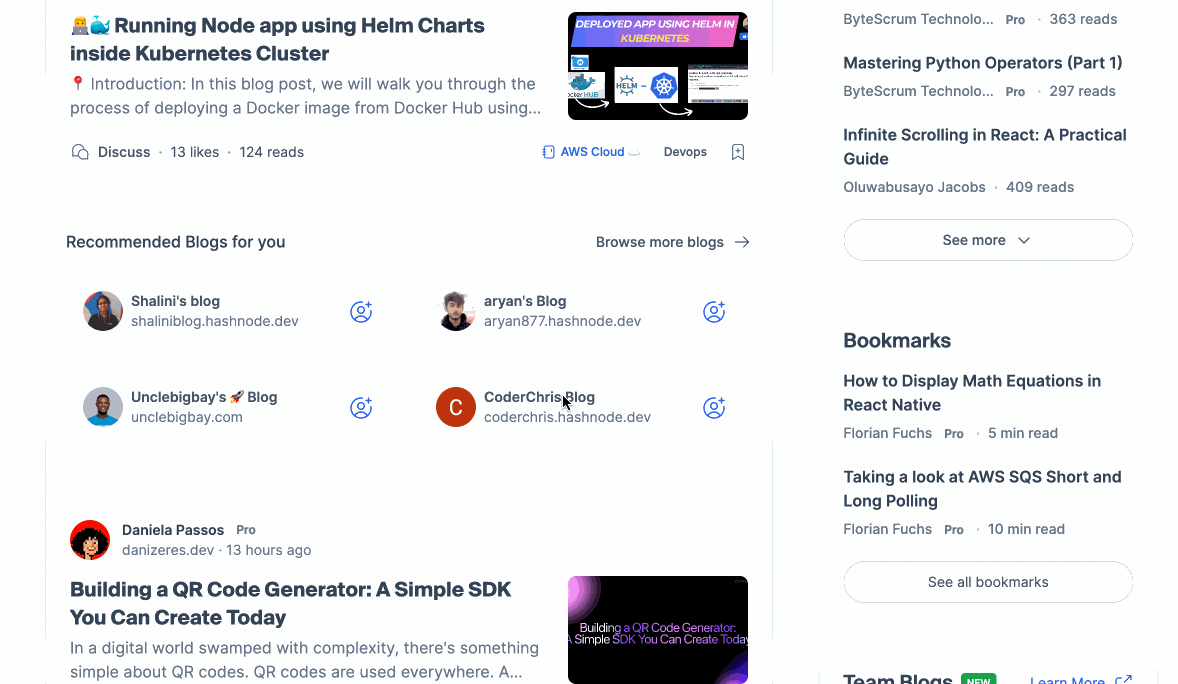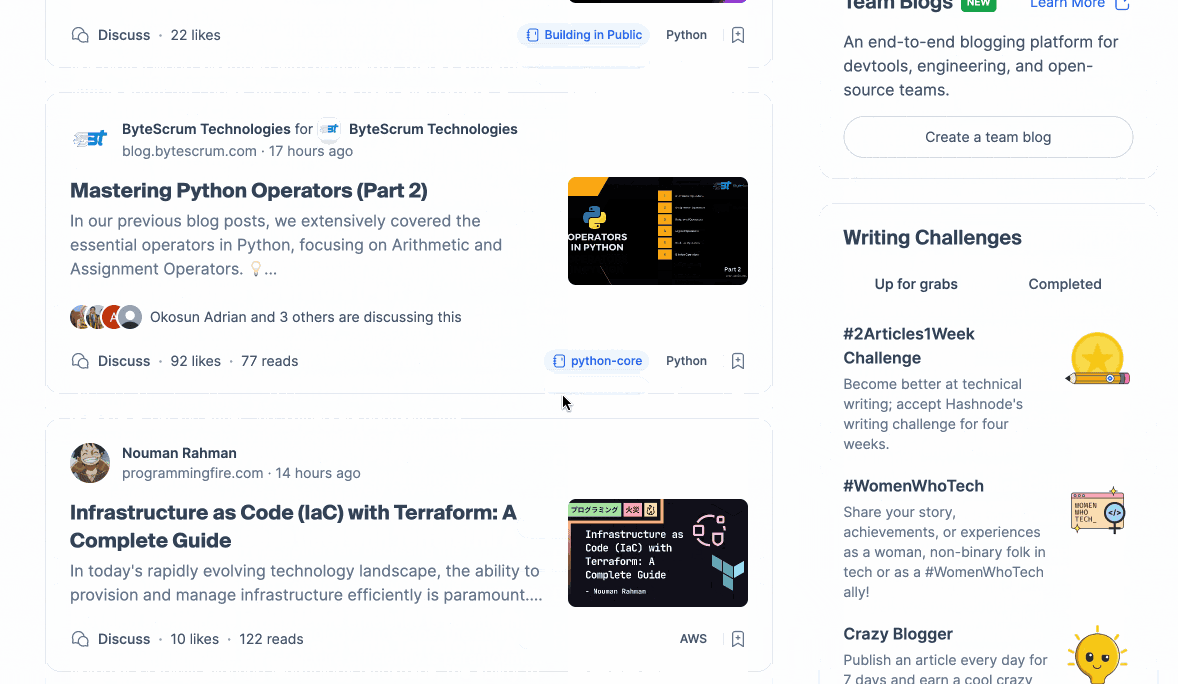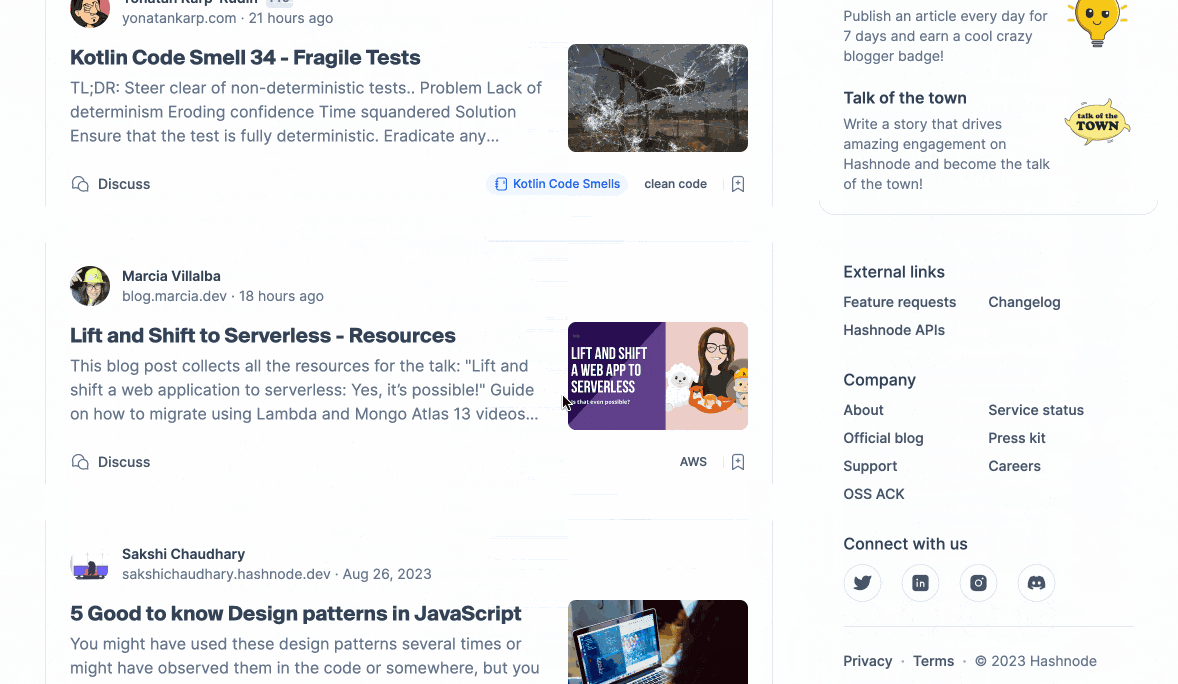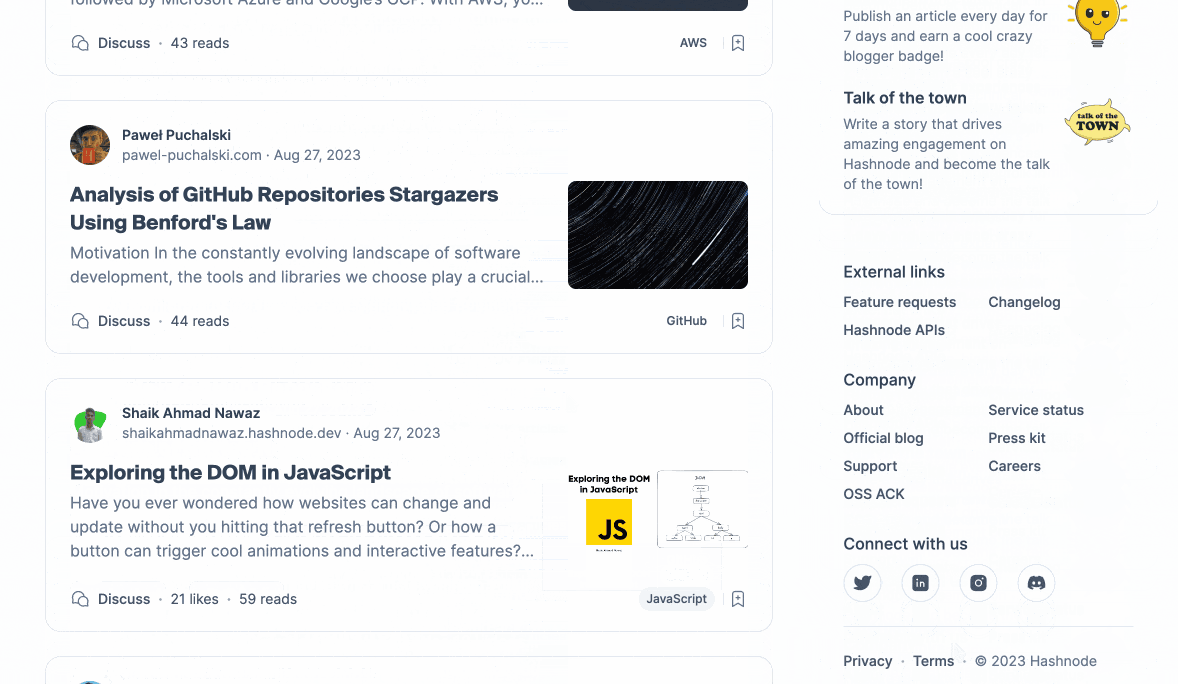
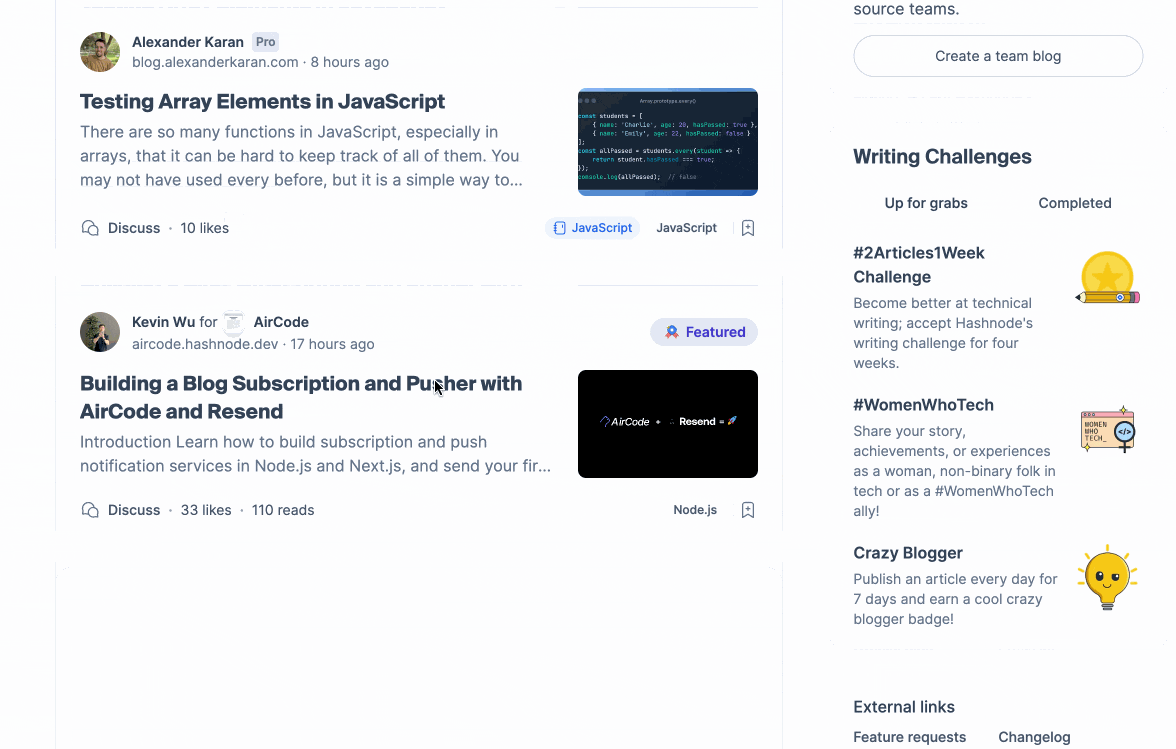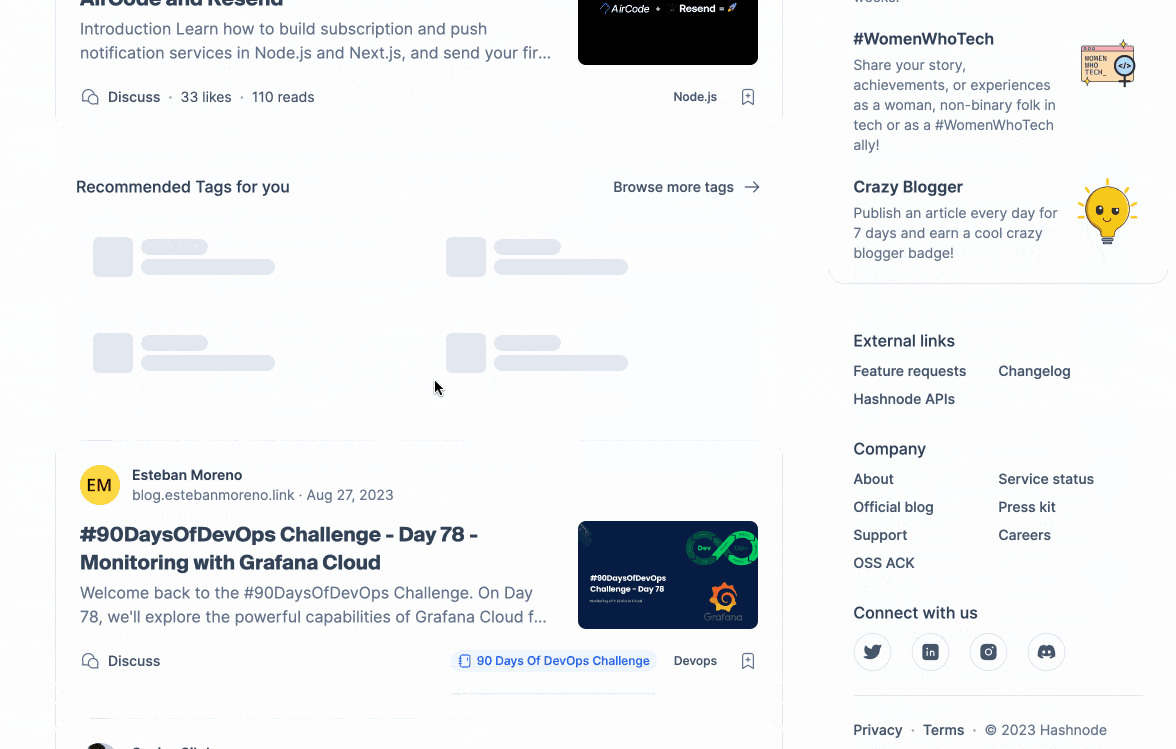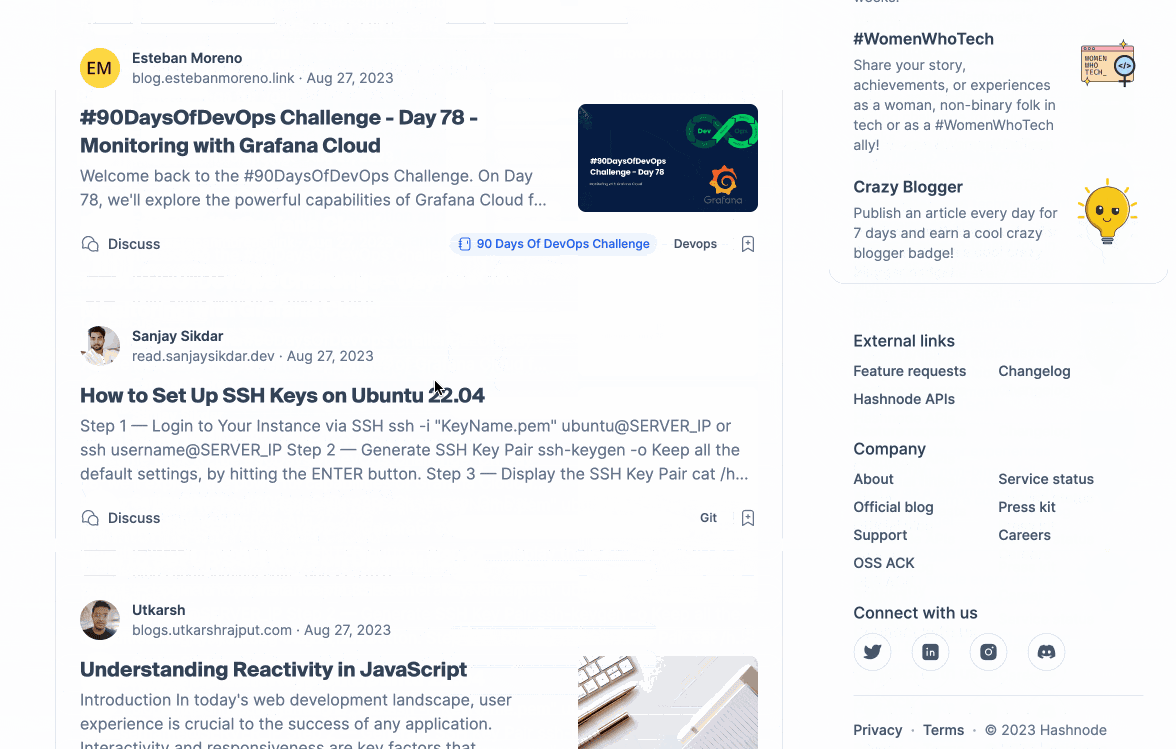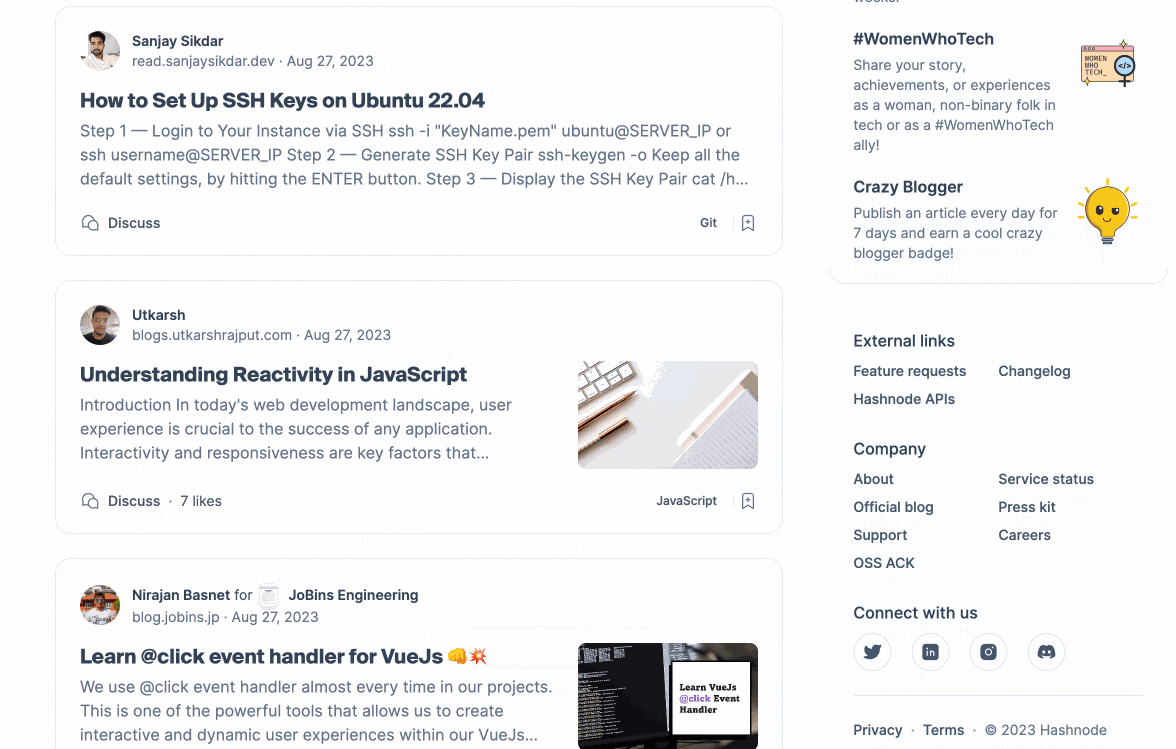
The users follow different tags and engage with Hashnode in unique ways. The outcome? A feed that is tailored to each user.
If you want to see this in action, visit our Homepage.
Let's see how we have built this experience from an engineering perspective 👀
How to generate personalized feeds without machine learning?
For most platforms, machine learning is the go-to approach to calculate and personalize stuff. These techniques and algorithms have existed for a long time and are rooted in the early e-commerce systems to recommend other stuff that you may find interesting.
Platforms like Facebook, Twitter, and Instagram have shown machine learning models can be effective when trained with enough and correct data.

At Hashnode, we decided initially not to go the machine learning route for our personalized feeds. Although incorporating machine learning into our platform is a long-term objective, we have opted for an alternative approach in the interim.
Starting with an ML approach is challenging. You need to have some knowledge about creating machine learning models and pipelines. You need to integrate ML into your existing platform. Multiple options are available: either go with self-hosting and self-creating/training your models or use a service where you can train models by feeding them data. The one point that stuck out was that you must understand your data and what you want to achieve with the model.
We decided to go with a ranking-based approach, as we wanted to verify assumptions we already had about our content and get out a better algorithm as fast as possible. To generate personalized feeds without machine learning, we have developed our own unique recipe for feed generation. This method considers various aspects and user behavior patterns that we believe will be most beneficial in ranking posts for each user. By carefully considering multiple factors, we can curate a feed that caters to our users' specific interests and needs.

Going with this route gives us the leverage to understand the influence different weights and data points have on the quality of our feed. It enables us to provide a more customized experience for our community members and continually refine and improve our feed generation process. Resulting in a faster delivery of even more relevant and captivating content as we gather more data and insights on user preferences and behavior.
In conclusion, while machine learning and AI algorithms are powerful tools for generating personalized feeds, traditional techniques can still be employed to create a tailored content experience.
Let's look at what we use to develop a personalized feed for a user 🫣
Which data is relevant for feed calculation?
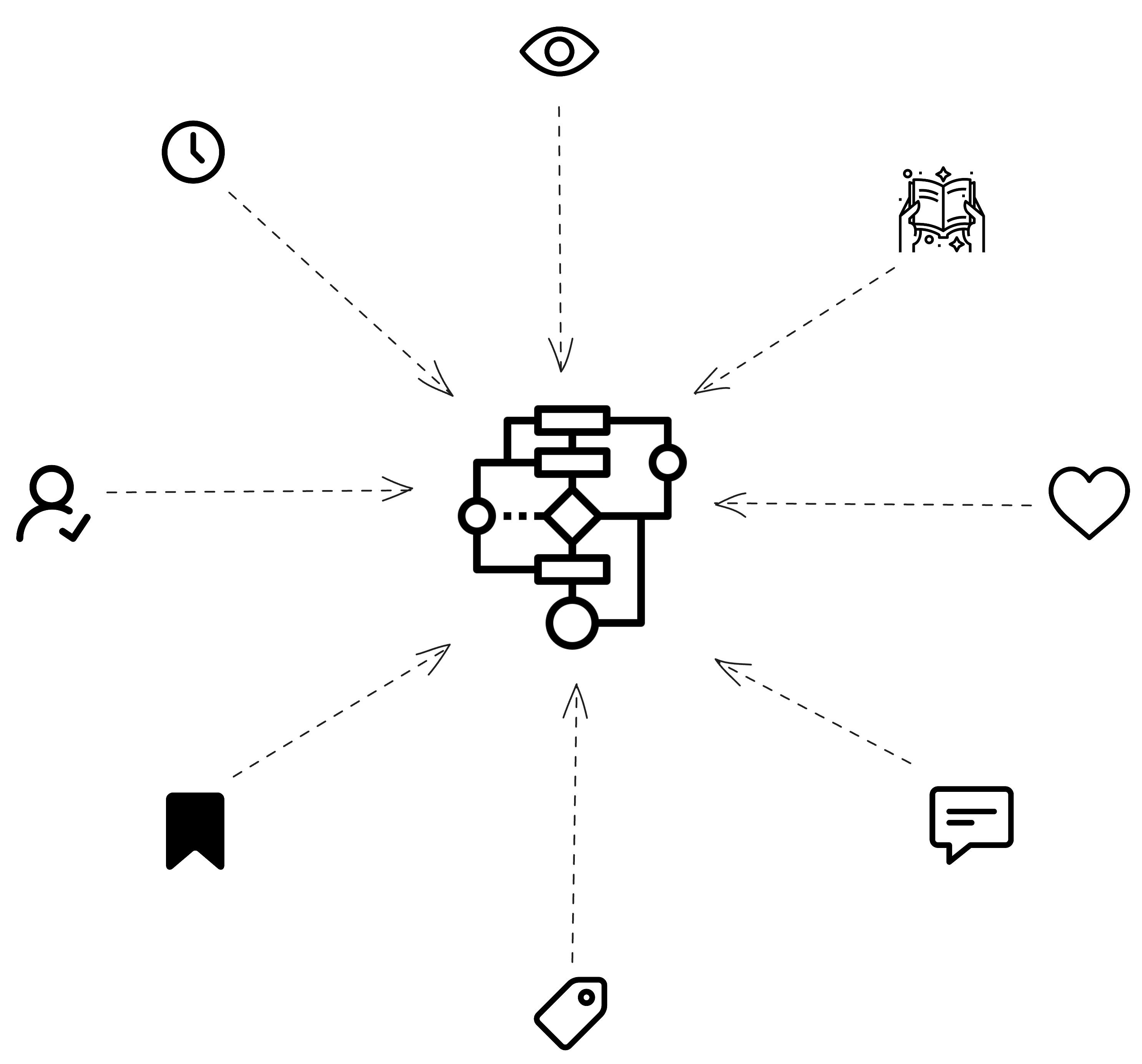
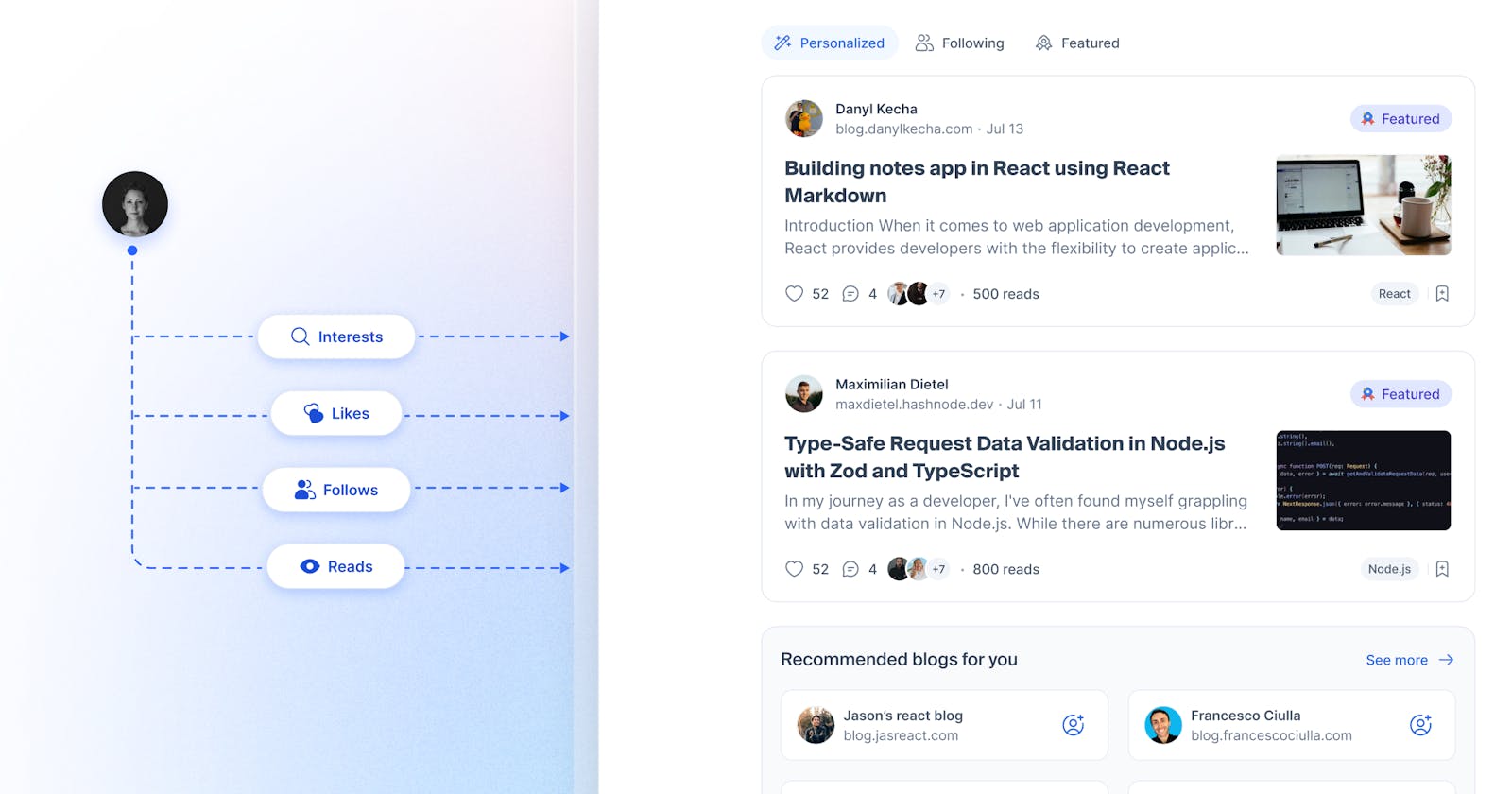
To effectively personalize feeds and generate accurate content rankings for each user, it is crucial to consider several pieces of data that can provide valuable insights into their preferences and behavior. These data points include:
User-specific:
Followed Tags: The tags a user follows indicate their topics of interest. Content with matching tags should be prioritized higher.
Following the Author/Blog: A user who follows an author or blog will likely enjoy that content source. Content from followed authors/blogs should be weighted more heavily.
Reading History: What articles a user has read in the past shows their preferred content types and subjects. Similar new content should be ranked higher.
Community-specific:
Likes: If an article has received many likes from the community, it is likely high quality and relevant to some users.
Comments: More engagement in comments also indicates relevance and popularity.
Views: Higher-viewed content is generally more relevant to more users.
Featured: Featured articles are chosen for their relevance and quality.
Recency: Newer content is likely fresher and more timely. Furthermore, this boosts newly published content and freshens up the feed.
Blog-specific:
Pro Account: Pro on a blog can indicate that the authors use Hashnode on a more sophisticated level and leverage features such as Hashnode AI, which allows them to generate even more high-quality content.
Custom Domain: Custom domains indicate authors leveraging Hashnode to build their brand and publish high-quality content.
Ranking posts to generate personalized feeds
Now, it's time to look at how weights are calculated and how they influence the score of a post within a user's feed. 🧑💻
The User-specific weights are rather straightforward. We can check if the user is following the Author/Blog, the following tags added to the post, and if the article is from an author in the reading history of the user:
const followingScore = usersUserIsFollowing.includes(
post.author
)
? FOLLOW_WEIGHT
: 0;
const readingHistoryScore = postsAuthorsUserHasViewed.includes(
post.author
)
? READING_HISTORY_WEIGHT
: 0;
const tagScore = calculateTagWeights(
tagsUserIsFollowing,
post.tags
);
const userSpecificScore = followingScore
+ readingHistoryScore
+ tagScore;
For the Community-specific weights, this is a little bit more difficult. We could go with a straightforward approach by deciding a weight for a single like and multiplying this with the likes this post has received, but the chance to over-boost a post becomes very high when going this route. Furthermore, this would not only result in potential over-boosts and decrease the relevance for the user, but it would also result in a non-uniform distribution of likes. Let's take a look at an example. Assuming two posts and a weight of 2 for each, like:
$$10(likes) * 2 = 20$$
and
$$100(likes) * 2 = 200$$
➡️ There is no way to compare these two as the values are too far apart.
The solution we came up with is twofold:
Normalize likes, views, and comments
Treat the weight for these parameters as the maximum a post can receive. For this, we need to update how we calculate the weight.
The formula can then look relatively easy. Let's retake a look at the likes for a post:
// Baseline value, everything over 1000 likes will recive the
// full score for the likes weight. Everything below will be fracitonal
// For 1000 as basline this will be 3
const MAX_LIKE = Math.log10(1000);
// For 10 likes this will be 1
// For 100 likes this will be 2
const postLikes = Math.log10(post.likes)
// Assuming 10 likes will result in: 1 * 2 / 3 = 0.66
// Assuming 100 likes will result in: 2 * 2 /3 = 1.33
const scoreForLikes = (post.likes * LIKES_WEIGHT) / MAX_LIKE;
// Check if the score is greater than the LIKES_WEIGHT
// Yes -> use LIKES_WEIGHT
// No -> use the calculated score
const actualLikeScore = scoreForLikes > LIKES_WEIGHT ? LIKES_WEIGHT : scoreForLikes
As we can see in the above snippet, this way of calculating the scores will ensure that:
An article with many likes is not over-boosted
The score does not exceed the weight we set as a maximum
The values are more evenly distributed, comparing
20to200(10times) vs.0.66to1.33(roughly2times)
This is done for all the Community-specific weights except the featured flag, which can be easily added by checking if the post is featured on Hashnode.
On the other hand, Recency also needs a specific logic to give us a desired score so we do not overboost newly published articles.
const getDateFactorForFeed = (date: Date) => {
// Consider the last 30 days in hours
const recentTimeFrame = 720;
// Divide the recent weight by the time frime to get the points
// each hour will recive
// e.g. 5 / 720 = 0.0069444444
const pointsPerHour = RECENT_WEIGHT / recentTimeFrame;
// Calculate the difference in hours between now and the publish date
// of the article
const difference = dayjs().diff(dayjs(date), 'hours');
// The weight should not be negative.
const weight = Math.max(recentTimeFrame - difference, 0);
// Multiple the resulting weight with the points for each hour
// weight = 0 => 0 * 0.0069444444 = 0
// weight = 720 => 720 * 0.0069444444 = 5
return weight * pointsPerHour;
};
With this calculation, the maximum value recency can receive will always be RECENT_WEIGHT.
Lastly, the Write-specific weights are calculated similarly to User-specific weights by checking if the Blog has connected a custom domain or is subscribed to Hashnode Pro.
The overall score calculation for the specific post adds up all our values, and we have a score for the post 🚀
How we keep your feed fresh all the time
After the initial testing, we noticed that the feed displays more relevant content but does not refresh as frequently as we would like.
How to make the feed highly dynamic and present fresh content on every visit?🤔
There are multiple possible solutions to do this, but we decided to explore damping. We don't want to harshly penalize articles by removing them from feeds. With damping, posts receive a slight reduction in their score if they have already been presented to the user. Moreover, this allows them to reappear in the feed and be noticed by the user. To ensure fair treatment for all articles, we have decided on the following rules:
The damping is based on the page an article is presented on
As the number of pages increases, the damping of articles on those pages decreases.
We will only implement damping for the first five pages, ensuring we do not inadvertently exclude any articles beyond that point.
After 24 hours, we remove all damping effects from a user's feed, allowing each post to potentially resurface in the upper positions.
In combination with the score calculation algorithm, this has a very nice effect:
Next plans for the personalized feeds on hashnode
Now that we have created an algorithm and prepared the groundwork, what comes next for our new personalized feed?
I assume you guessed it right:
{kind=link}
Initially, we only wanted to verify our assumptions about content and how to create a feed that engages users and shows high-quality and highly relevant articles from our Platform.
As you can imagine, the calculation is expensive from a computational point of view. We need to gather the latest posts from our platform, collect data for the user, and calculate the scores for each post before we can serve them. It is also not as straightforward as it would be with a following feed. There, we could cache everything and append new posts on the top of the cache to be served on a request to the feed.
In the case of a personalized feed, we need to have the user metadata at hand to correctly assign a score to the article for the user based on the algorithm.
Guess what? We've developed a nice solution that I'll dive into in another article! But here's a little sneak peek: We're pre-calculating the personalized feed for all our active users on the platform! This way, we can slash peak loads on our service and serve the feed at lightning-fast speeds! 🚀💥🏎️
Until the next one,
Cheers 🙌