


Hashnode's Feed Architecture
How Hashnode calculates feeds on scale and serverless


Table of contents
We previously explained how we calculate the Hashnode Feed and select content and metadata for each user. We found that the feed now displays improved and personalized content. However, we did find two issues in the implementation:
Performance: The Feed calculation is not trivial; thus, it slows down the access to our main page.
Security: Many expensive queries and aggregations are needed to gather all the data required for the calculation. Safeguarding our database from excessive usage is a must.
Speeding up the page, keeping our databased safe, and showing the freshest content for you on the Hompage was the inspiration for building Feeds on steroids: a scalable and serverless architecture to pre-calculate feeds for recurring users 💊
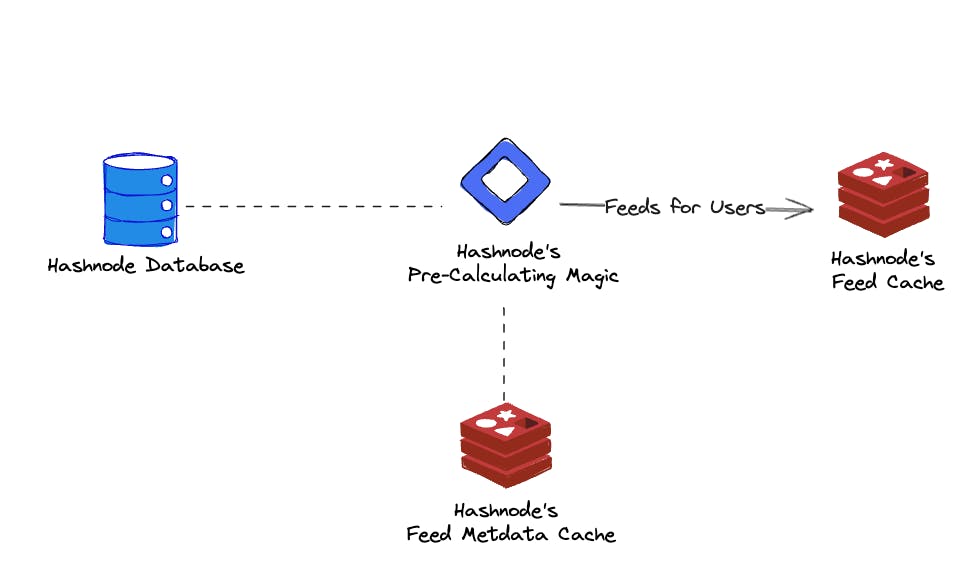
To optimize page speed, we found that pre-calculating feeds for users is the best option. This means we don't have to calculate the feed every time a user visits our feed page. Instead, we can return the feed from the cache and make page loading times faster. A crucial enabler for this is using a cache. With the fast access a cache offers, we can directly load the feed from there to be presented for our users. The above image shows this in a very high abstraction. We are calculating feeds using data from our internal database and a cache for relevant metadata. The calculated data is then stored in a cache for quick access.
Let's take a look at how everything comes together in detail ⬇️
Pre-calculating feeds for thousands of users with AWS Step Functions 😎
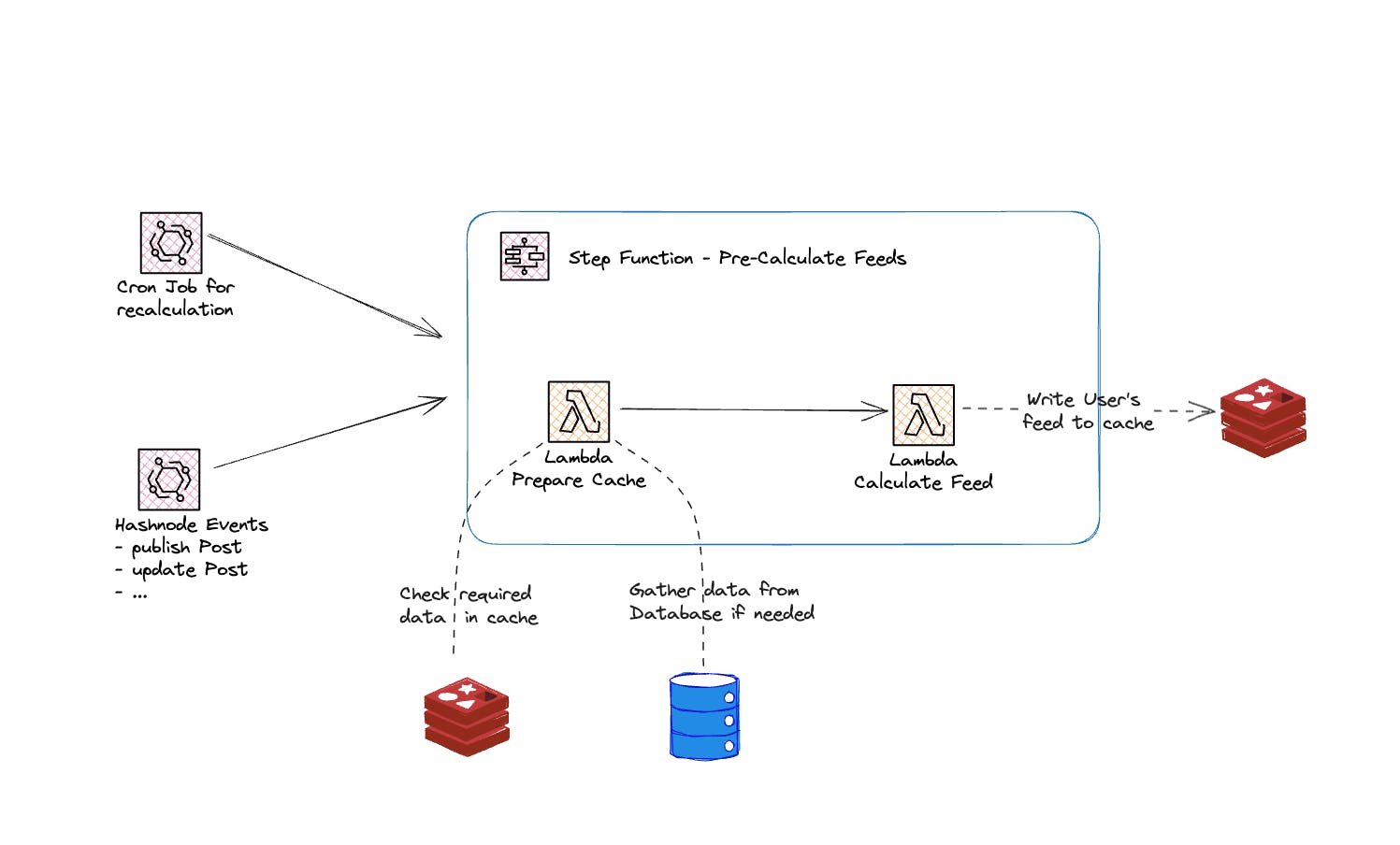
We calculate the feed for each user based on internal Hashnode events. These events require a re-calculation of the feeds. An example here is publishing a new post on Hashnode.
Prepare the cache: Before we start calculating each feed, we must ensure that all data required is in the cache. The final calculation step is wholly based on the cache. This includes user metadata, relevant data for posts, and active users for whom we are pre-calculating. If data is unavailable in the cache or too old for usage, we pull fresh data from our internal database.
Calculate the feed: We start the actual calculation when all data is prepared and ready in the cache. We use an AWS Step Function feature called distributed map execution to do this in parallel. We can calculate multiple feeds simultaneously and reduce execution time. Each calculation has its own AWS Lambda function.
If each user's feed would be calculated on the fly, we would see longer loading times on Hashnode's main page. To do the calculation, we need a lot of data. We must get all the data from the database. This will affect other queries. Lastly, a simple approach like that seems wasteful. We are pulling in the same data again and again for the calculation without reusing it.
The above architecture reference shows the feed pre-calculation process. We utilize a couple of services to achieve a performant recalculation on various triggers:
AWS Lambda
AWS Step Functions
Redis Cache
Distributed Maps in Step Functions
Amazon EventBridge
Once an event that requires feed re-calculation reaches the AWS Step Function, we will run different checks and collect the necessary data. A new feed for each active user on our platform is then generated. We minimize database access and store necessary data in a cache for fast access. Utilizing our event-driven architecture allows us to react to different events within the system and keep the cache up-to-date.
Let's look at the core parts and what's happening there.
Preparing data in the cache
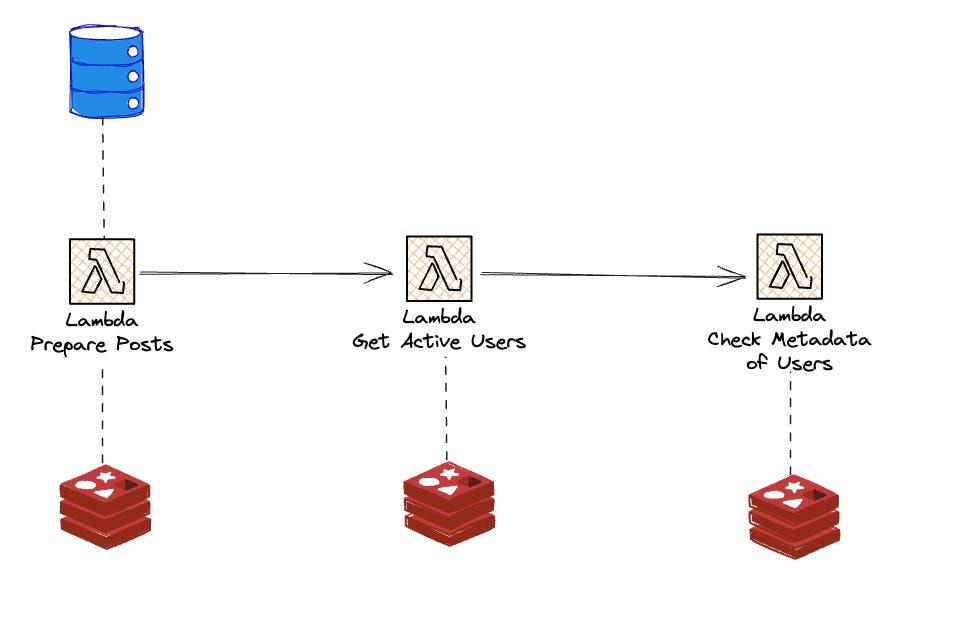
When an event triggers an AWS Step Function, we must have all the required data for the calculation step. The first step is to check if the cache has valid data. If not, fill it. The main data for feed calculation are posts. The first AWS Lambda in the AWS Step Function execution will check if we have valid data in the cache for the posts we base our calculation on. Valid in this context refers to data that is not outdated and available in the cache.
Once this is resolved, we can go to the next ingredient for calculation: getting the active users. When no active user is found, we skip the further execution altogether.
Based on the active users, we can now check if the personalization component, the user's metadata, is available in the cache. If metadata is found, we can directly calculate the feed. Otherwise, we have to collect the metadata beforehand from the database and save it to the cache.
These last two steps are done by utilizing distributed maps. One map for users whom we have found valid metadata in our cache. One for users where no metadata data was found, and we need to collect it before starting the actual calculation
Distributed map for users where metadata is available
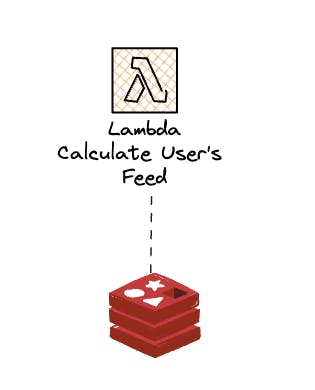
We find valid metadata for a user. The previous steps of our AWS Step Function provided all the required data. We can now start calculating the user's feed directly. Notice how no database is involved in this step anymore.
Distributed map for users where metadata is not available
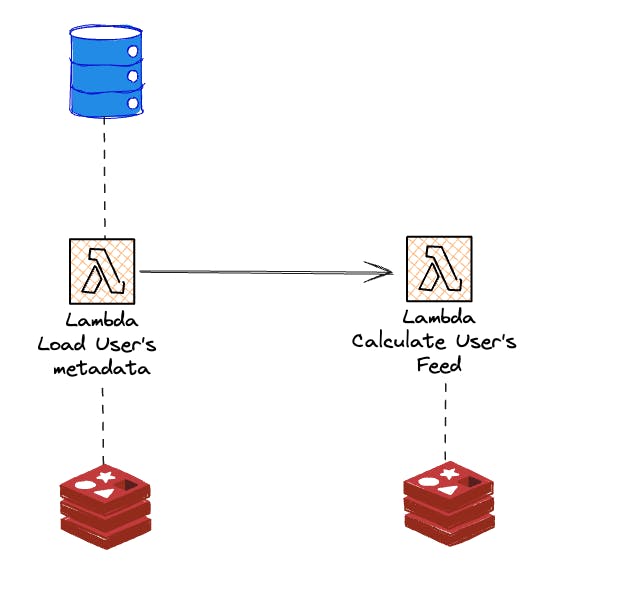
No metadata found for the user requires us to prepare it before starting the calculation. A preceding AWS Lambda function handles this before the actual calculation is done. The database is queried to collect the user's metadata, and the result is stored in our cache. Again, the calculation step does not require any database connection to do its job.
The two distributed maps share the same final step of the feed calculation. Once succeeded, we save the result, the user's feed, in the cache for fast access via our APIs. To make the process faster and use less bandwidth, we use item batching in the AWS Step Function. This allows us to share post data with the items in the same batch. We would have to get the post data and metadata information for each user otherwise.
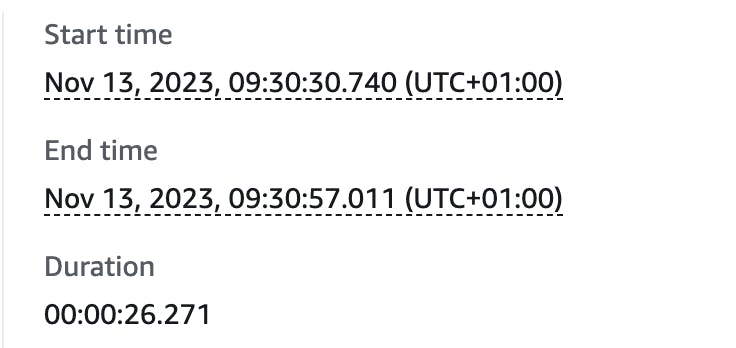
A typical AWS Step Function run has a duration of ~26 seconds - while calculating the feed for thousands of users 🚀
Getting rid of stale data - Purging and re-calculating feeds on a period
We decided to purge the whole cache regularly, even though we have implemented householding for our cache. We also have various steps in the AWS Step Function that validate cache data before the calculation is done.
A cron job runs the AWS Step Function every couple of hours to delete all data in the cache. This is a safety measure and reassurance that we only store essential data briefly. We can ignore events that may affect the feed for a longer time. The updates from these events will be included after the next purge. This is a nice bonus. This saves some implementation effort for low-priority events regarding feed re-calculation. The AWS Step Function will refill the cache when the feed is empty.
Final words
This post should give you a rough idea of calculating feeds on the scale and which services we apply. Are you interested in more feed-related content? If so, let us know in the comments - we have a couple more crips implementation details ready to be published 🙌
Cheers 🙌