


Hashnode's Overall Architecture
How Hashnode runs on a scale (almost) completely serverless 🤔


This article gives you an overview of the architecture of Hashnode. The goal of this article is to give you a broad architecture of our involved services.
Overall Architecture
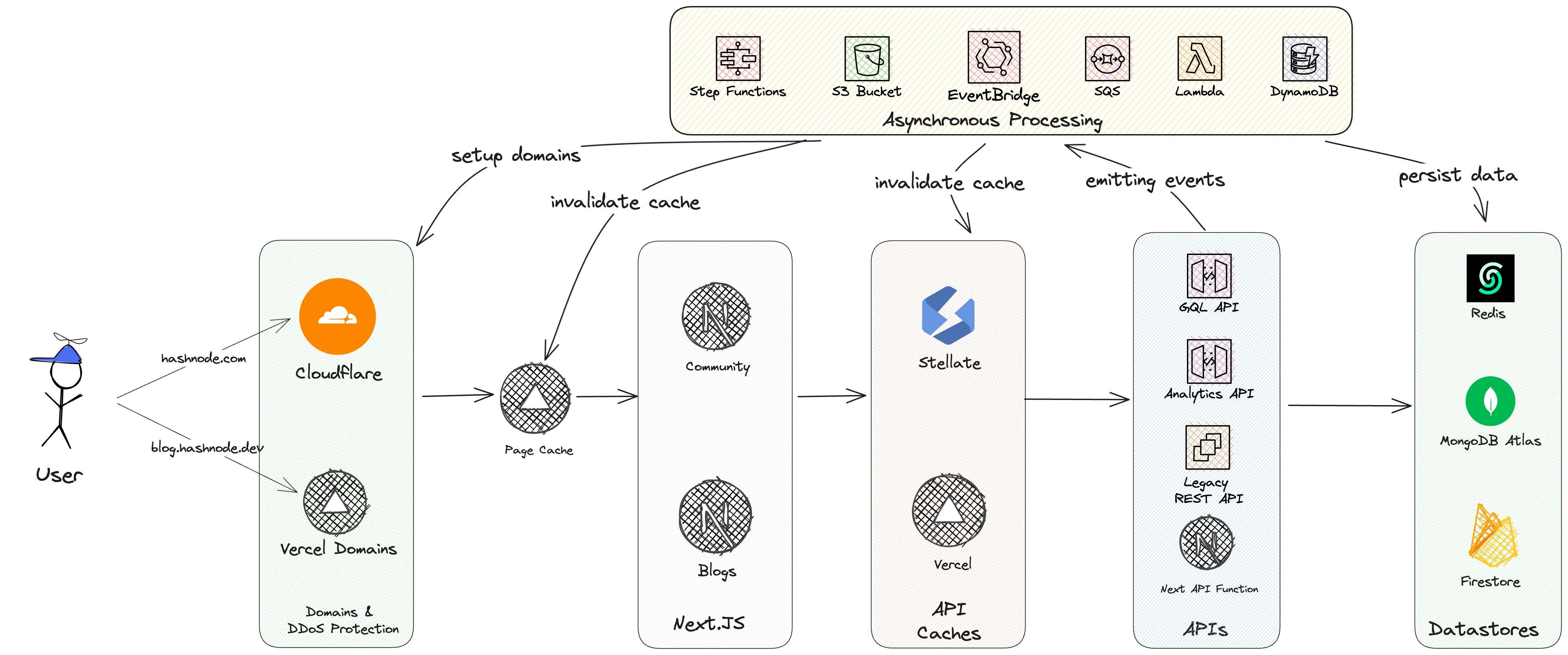
This is our overall architecture. A request starts on the user's side. It depends on which site the user visits exactly:
Blog Frontend: For example, engineering.hashnode.com
Community Frontend: hashnode.com and all sub-pages
Let's walk through each step.
Domain & DDoS Protection

The first step the request takes is either through Cloudflare or Vercel. It depends on which route you are trying to access:
hashnode.com -> This is Hashnode's community page. This route is protected by Cloudflare
blog.hashnode.dev or a custom domain -> This is our blog frontend. All custom domains and blog frontends hit Vercel directly.
One main feature of Hashnode is the usage of custom domains. With Vercel's API, we can easily add new custom domains and Vercel takes care of provisioning the certificates and redirecting to the correct Vercel project. We are one of the biggest customers on Vercel for using their custom domain functionality.
It also offers DDoS protection, edge caches, CI/CD, and more.
Cloudflare protects our systems from DDoS attacks as well. It is also our DNS system.
Page Cache
Next, we will hit the page cache from Vercel.
Why another caching layer?
As we can see in the next steps, we have two layers of caches.
Page Cache (this one)
API Cache (see later)
The page caches ensure fast performance for end users because the whole HTML page is cached on the edge. This will enable fast access to the actual site without the need for any API and database calls.
How Hashnode uses the cache.
Once Vercel introduced getServerSideProps (server-side rendering) Hashnode adopted this caching mechanism with a very short revalidation time period. Back then there was no possibility to revalidate the cache via an API.
This is why we employ a very brief time frame, after which the cache enters a stale state. This can still have a lot of negative consequences for your downstream systems.
Once Vercel announced Incremental Static Regeneration (ISR) it was possible to invalidate the cache via an API. There are some issues while we can't use ISR effectively which we will point out in more detail in the future.
We addressed this issue by implementing a very short page cache revalidation period, along with maintaining an always up-to-date API cache, which you will see shortly.
Stale-While-Revalidate (SWR)
The cache follows the stale-while-revalidate approach.
Once data is present in the cache it will be available for fast access. After a certain time, the data will be marked as stale. The data is still available in the cache and will be returned in the response. But at the same time, the data will be updated in the background from the origin. This ensures that the next request(s) get fresh data. It also ensures fast access for end-users.
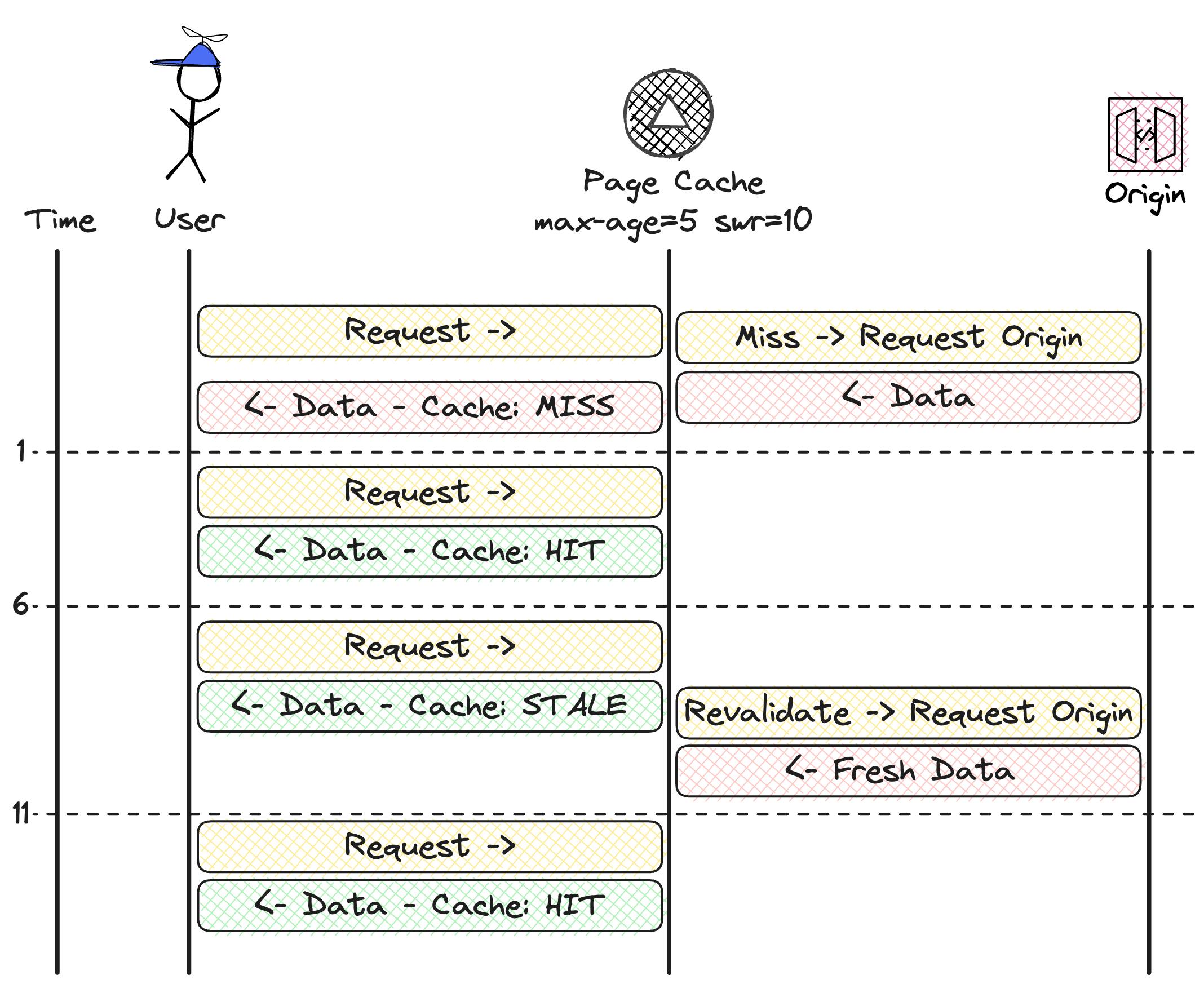
In the example above we have the following cache-headers set: max-age=5 swr=10.
This means data is fresh for 5 seconds and stale data can be returned for another 5 seconds. Before time 1 a request came in and filled up the cache. Now fresh data is available for the next 5 seconds.
Once the request at time 6 hits the cache it returns stale data. The cache provider returns the data in the response but gets fresh data from the origin at the same time. By doing that we're not decrementing the performance of this request and get fresh data for the next request at time 11.
Next.JS Server
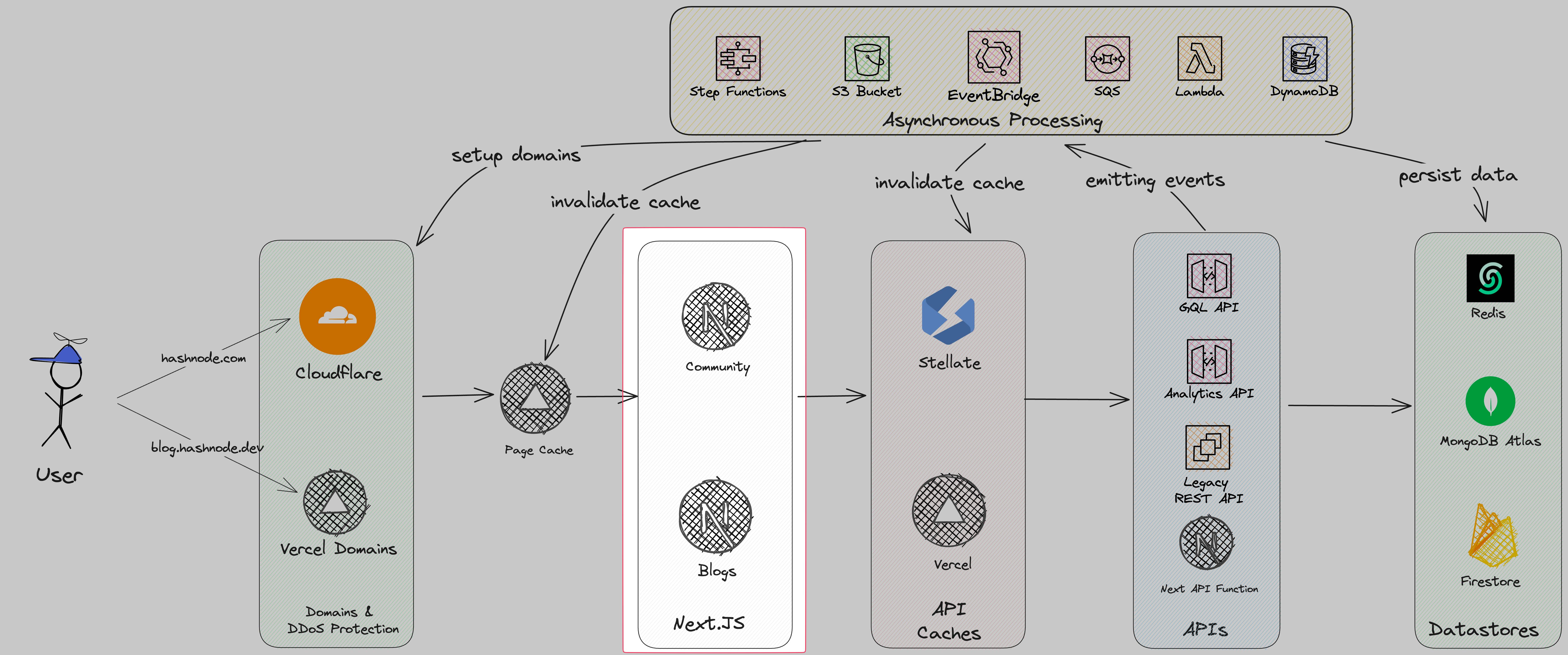
The next step is our Next.JS servers. Depending on which route you are going to (community vs. blogs) a different Next.JS server will be used.
The Next.JS server takes care of multiple things:
Server-Side rendering pages
Statically rendering pages
Client-side rendering
We are mostly using the pages directory but are slowly migrating to the app directory.
API Caches
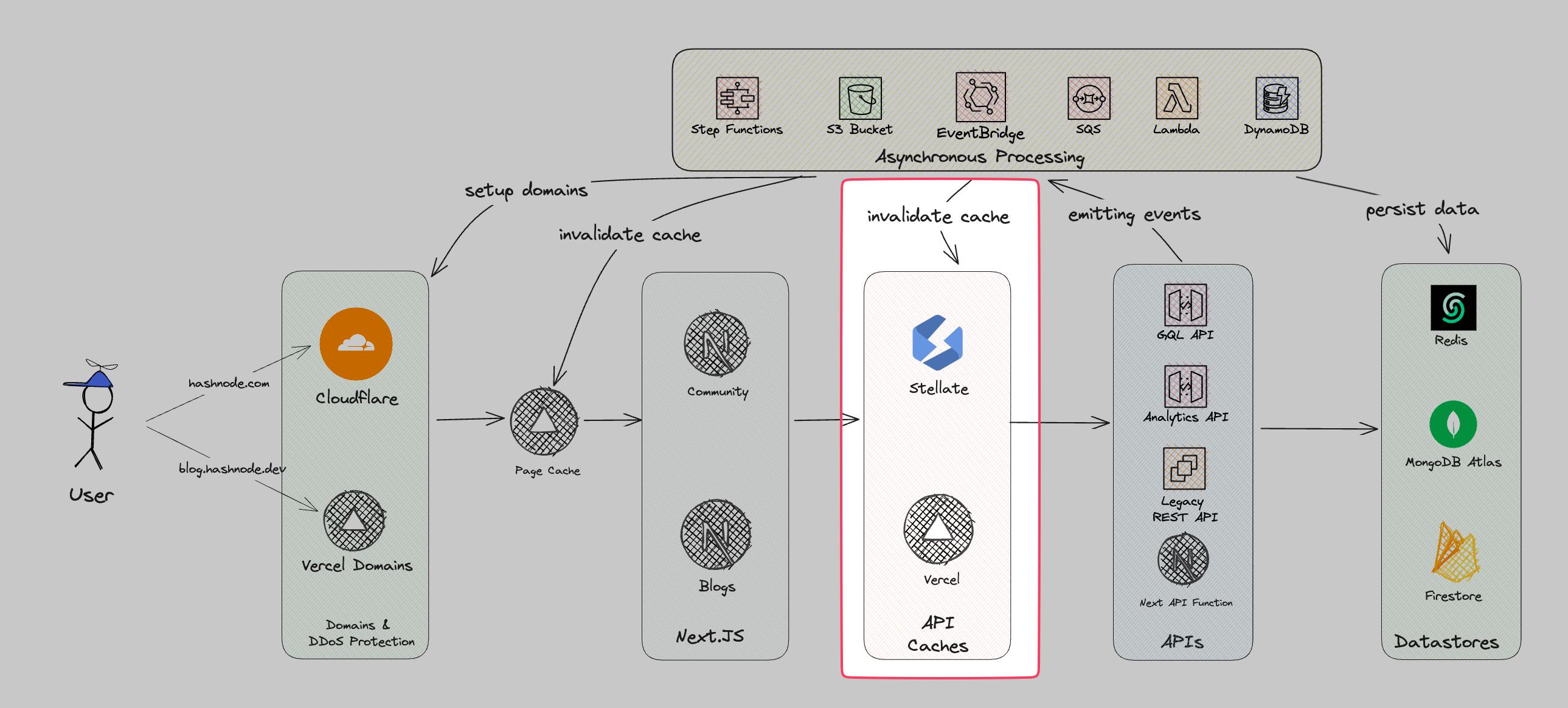
In the next step, the API caches are accessed. API Caches are caching API responses. There are two kinds of caches we use:
GraphQL Edge Caching with Stellate
Serverless Function Caching with Vercel
GraphQL Edge Caching
We use a GraphQL API. To be able to cache queries on the edge we make use of Stellate. Stellate edge caches our GraphQL queries.
Vercel Serverless Function Caching
We still make use of serverless APIs in Next.JS. We cache these functions on Vercel. This is mostly due to legacy reasons.
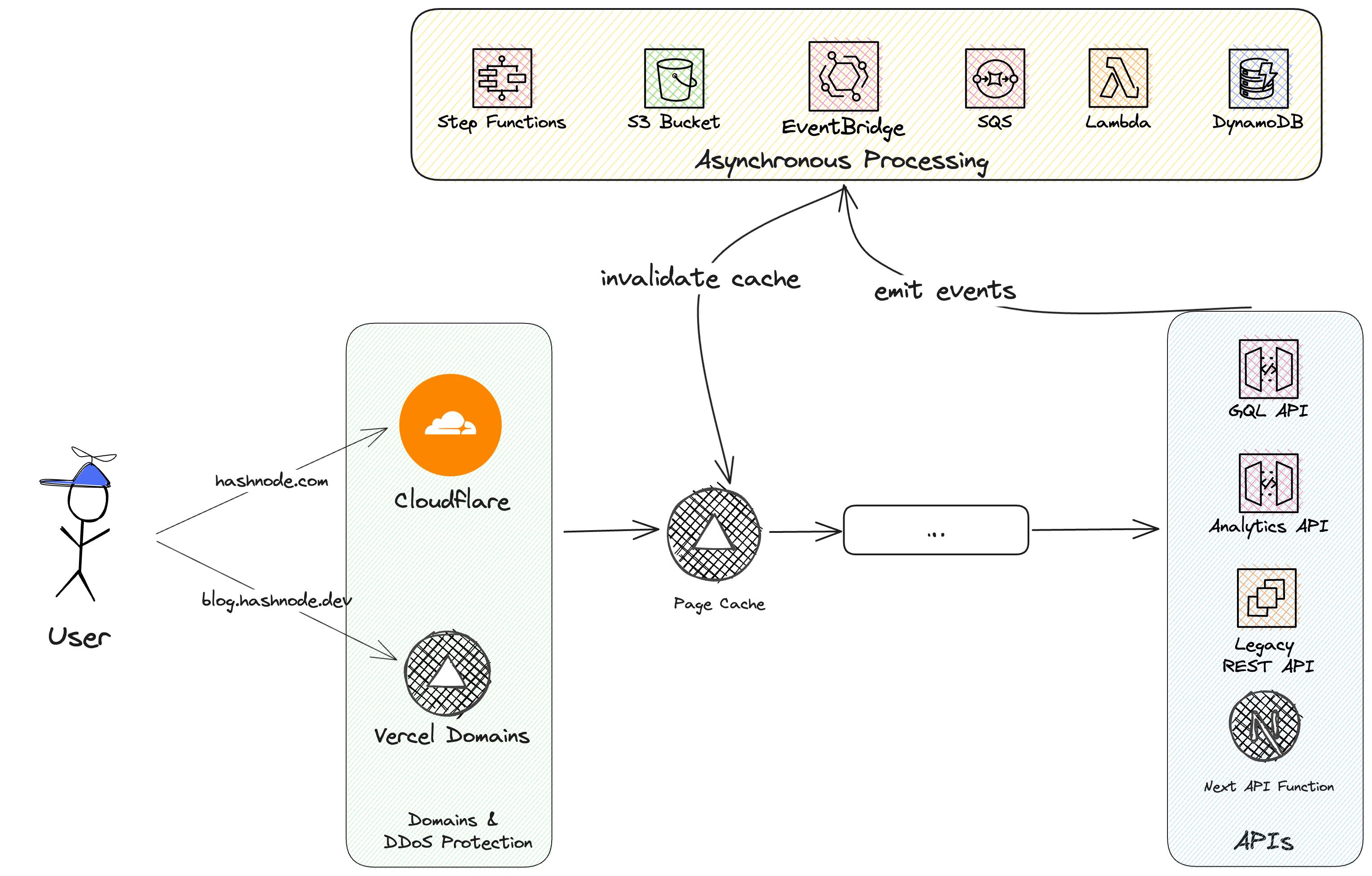
Cache Invalidation
Both caches follow a SWR approach. After some time data will be updated from the origin. But this is not optimal. In the best-case scenario, we want to be able to cache data for a very long time period and only update the data on certain events.
This is where our event-driven architecture (EDA) comes into play. Each user action emits events. For example, if users are:
publishing a post
liking a post
updating their custom domains
we have consumers that listen to these events and execute business logic on top of that. Many events will call the purging API of Stellate and invalidate the cache.
With this approach, we are able to cache data for a very long time period and only hit our origin if it is really necessary.
APIs

We currently have multiple APIs. For the actual business logic, we make use of 3 APIs. This is mainly due to legacy reasons.
Express REST API running on Lightsail - legacy
Next.JS API Routes on Vercel - legacy
GQL API running on API Gateway & Lambda - new
Very early on we started with an express JavaScript REST API. After moving to Vercel we made more use of Next.JS API functions. With the time and increasing pains, we started to build a dedicated GraphQL API.
The GraphQL API runs fully serverless on AWS. It uses the following stack:
Serverless Stack (SST) for deployment and development
Amazon API Gateway
Lambda as business execution handler
Apollo 4 as the GraphQL Server
The API is also available for the public to use.
All APIs emit certain events. This is the backbone of Hashnode EDA.
There is one additional analytics API. This API takes care of tracking page views, publication visits, and more.
Datastores
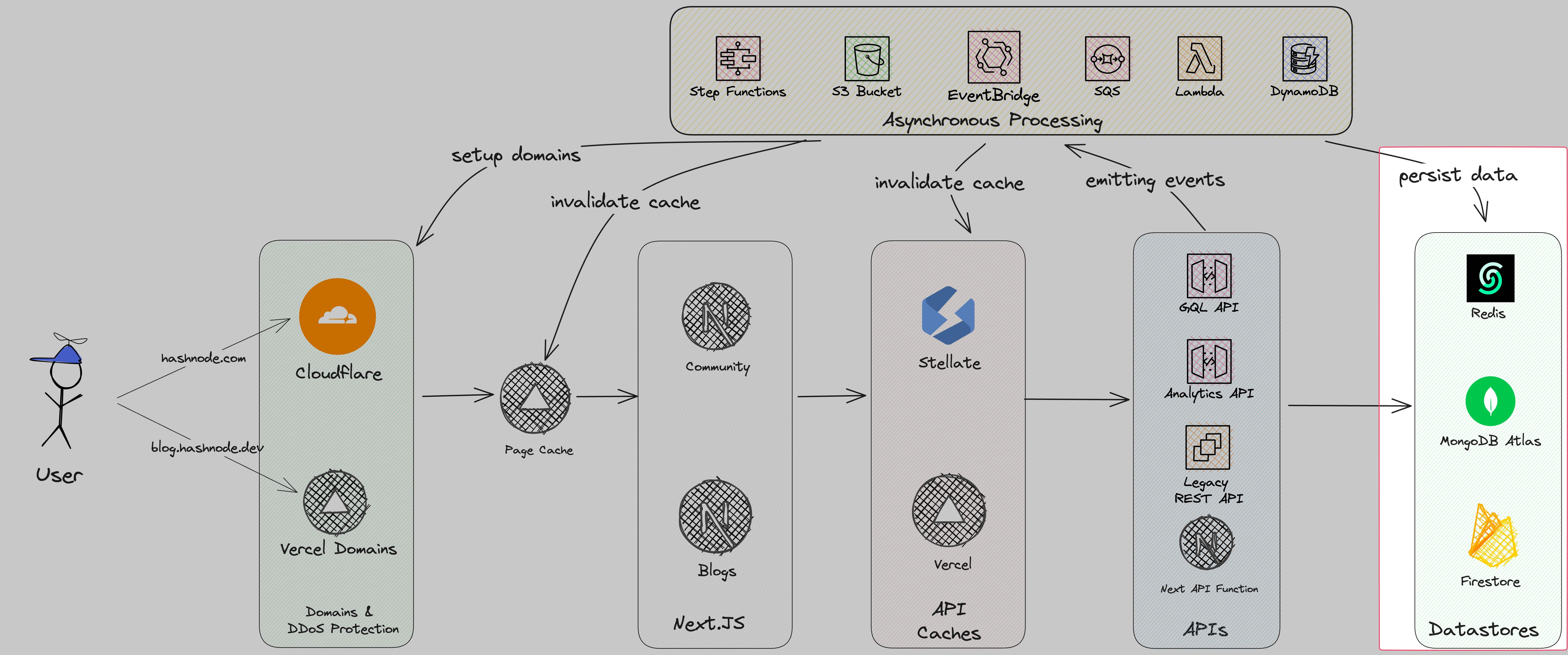
The APIs and the asynchronous processes are persisting the data in three different data stores:
MongoDB: Our main database is MongoDB deployed on Atlas
Google Firestore: Firestore holds all our drafts
Redis: Redis is used for custom caches. For example, the feed pre-calculation
Our main data store is MongoDB. MongoDB gives us the flexibility of No-SQL with additional capabilities to make basic aggregations with aggregation pipelines. MongoDB is deployed on Atlas so that it has fewer issues with infrastructure handling.
As a second data store, we use Firestore. Firestore was used very early on in the days of Hashnode. Firestore holds all our drafts.
The last data store we use is Redis. We have several smaller use cases on Redis. The main use case is our personalized feed. The feed computation can be quite heavy. This is why we calculate this feed for daily active users so that they have a good performance. We use Upstash as a managed Redis provider.
Asynchronous Processing
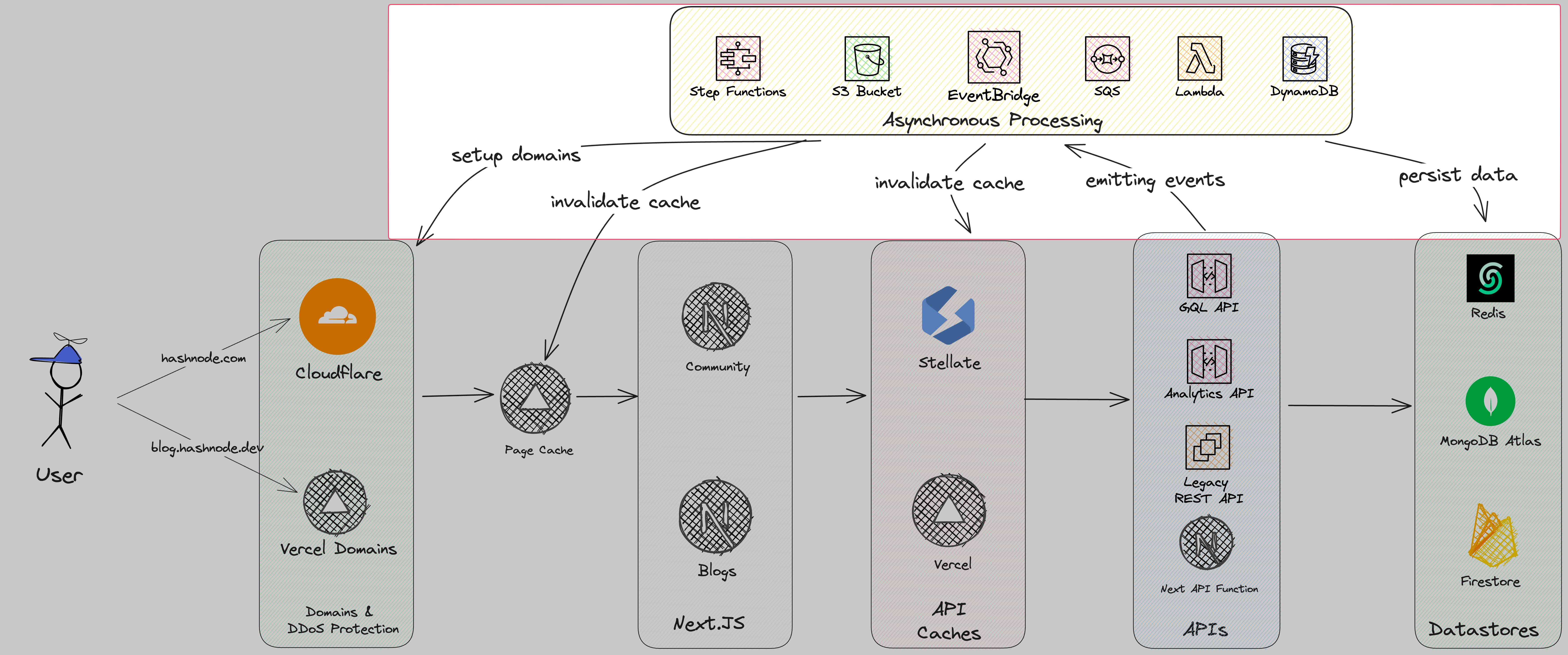
The heart and backbone of Hashnode is the asynchronous processing and event-driven architecture. Everything until now was a synchronous workload. That means the user needed to wait until it was finished. For example, if the user published a post the user saw a loading indicator until the post went the route of vercel -> next -> AWS -> MongoDB and back.
Asynchronous processing is everything that runs in the background. Hashnode makes use of an event-driven architecture. That means for each action a user is doing some event will be emitted. Some examples of events are:
post_publishedpublication_pro_access_changeduser_signed_uppost_liked
... and 62 more!
Based on these events several actions happen.
For example, after you publish a post we do the following actions:
Purge caches
Send newsletter if subscribers are enabled
Update analytics
re-calculate feed
... etc.
This makes our architecture very decoupled and flexible. Consumers can subscribe to events without intervening with any other ongoing work. Features like cache invalidations, newsletter imports, or sending out a lot of emails are possible thanks to that.
The whole EDA runs in a serverless way with AWS Services like
EventBridge
Lambda
SQS
SNS
Step Functions
... and many more.
That's it 🎉
This post should give you an overview of each part of our architecture. Are you interested in more or in anything in detail? Let us know in the comments!